Web LLM
Llama 2 7B/13B are now available in Web LLM!! Try it out in our chat demo.
Llama 2 70B is also supported. If you have a Apple Silicon Mac with 64GB or more memory, you can follow the instructions below to download and launch Chrome Canary and try out the 70B model in Web LLM.
Mistral 7B models and WizardMath are all supported!
This project brings large-language model and LLM-based chatbot to web browsers. Everything runs inside the browser with no server support and accelerated with WebGPU. This opens up a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration. Please check out our GitHub repo to see how we did it. You can use WebLLM as a base npm package and build your own web application on top of it by following the documentation.
We have been seeing amazing progress in generative AI and LLM recently. Thanks to the open-source efforts like LLaMA, Alpaca, Vicuna and Dolly, we start to see an exciting future of building our own open source language models and personal AI assistant.
These models are usually big and compute-heavy. To build a chat service, we will need a large cluster to run an inference server, while clients send requests to servers and retrieve the inference output. We also usually have to run on a specific type of GPUs where popular deep-learning frameworks are readily available.
This project is our step to bring more diversity to the ecosystem. Specifically, can we simply bake LLMs directly into the client side and directly run them inside a browser? If that can be realized, we could offer support for client personal AI models with the benefit of cost reduction, enhancement for personalization and privacy protection. The client side is getting pretty powerful.
Won’t it be even more amazing if we can simply open up a browser and directly bring AI natively to your browser tab? There is some level of readiness in the ecosystem. This project provides an affirmative answer to the question.
Instructions
WebGPU just shipped in Chrome 113.
Select the model you want to try out. Enter your inputs, click “Send” – we are ready to go! The chat bot will first fetch model parameters into local cache. The download may take a few minutes, only for the first run. The subsequent refreshes and runs will be faster. We have tested it on Windows and Mac, you will need a GPU with about 6GB memory to run Llama-7B, Vicuna-7B, and about 3GB memory to run RedPajama-3B.
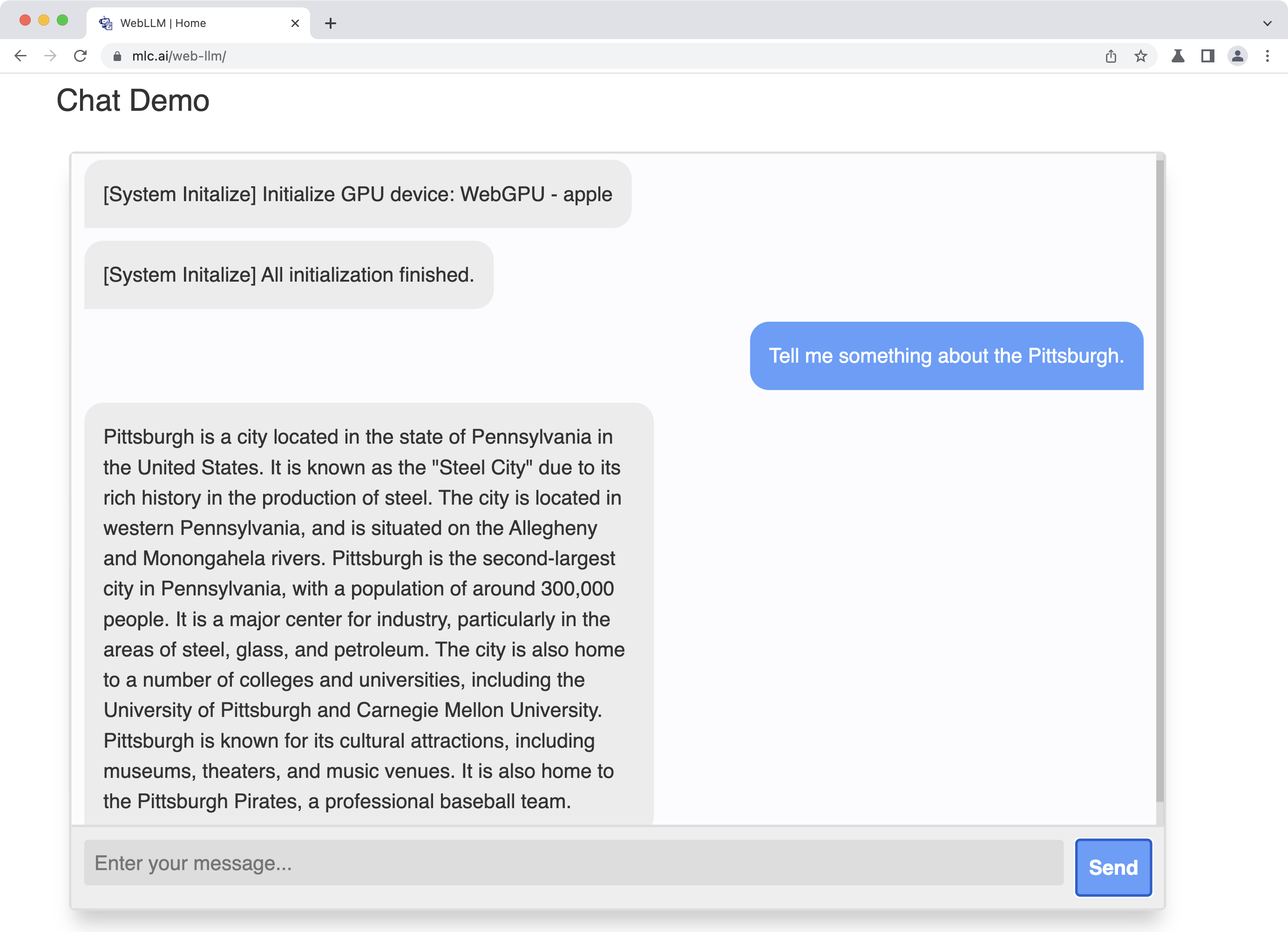
Chat Demo
The chat demo is based on Llama 3, Gemma, Mistral-7B and its variants, and many more. More model supports are on the way.
Models with “-1k” suffix signify 1024 context length, lowering ~2-3GB VRAM requirement compared to their counterparts. Feel free to start trying with those.
Links
- Web LLM GitHub
- You might also be interested in Web Stable Diffusion.
Disclaimer
This demo site is for research purposes only, subject to the model License of LLaMA, Vicuna and RedPajama. Please contact us if you find any potential violation.