Introduction to MLC LLM¶
Machine Learning Compilation for Large Language Models (MLC LLM) is a high-performance universal LLM deployment engine. The mission of this project is to enable everyone to develop, optimize and deploy AI models natively on everyone’s devices with ML compilation techniques.
This page is a quick tutorial to introduce how to try out MLC LLM, and the steps to deploy your own models with MLC LLM.
Installation¶
MLC LLM is available via pip. It is always recommended to install it in an isolated conda virtual environment.
To verify the installation, activate your virtual environment, run
python -c "import mlc_llm; print(mlc_llm.__path__)"
You are expected to see the installation path of MLC LLM Python package.
Chat CLI¶
As the first example, we try out the chat CLI in MLC LLM with 4-bit quantized 8B Llama-3 model. You can run MLC chat through a one-liner command:
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
It may take 1-2 minutes for the first time running this command. After waiting, this command launch a chat interface where you can enter your prompt and chat with the model.
You can use the following special commands:
/help print the special commands
/exit quit the cli
/stats print out the latest stats (token/sec)
/reset restart a fresh chat
/set [overrides] override settings in the generation config. For example,
`/set temperature=0.5;max_gen_len=100;stop=end,stop`
Note: Separate stop words in the `stop` option with commas (,).
Multi-line input: Use escape+enter to start a new line.
user: What's the meaning of life
assistant:
What a profound and intriguing question! While there's no one definitive answer, I'd be happy to help you explore some perspectives on the meaning of life.
The concept of the meaning of life has been debated and...
The figure below shows what run under the hood of this chat CLI command. For the first time running the command, there are three major phases.
Phase 1. Pre-quantized weight download. This phase automatically downloads pre-quantized Llama-3 model from Hugging Face and saves it to your local cache directory.
Phase 2. Model compilation. This phase automatically optimizes the Llama-3 model to accelerate model inference on GPU with techniques of machine learning compilation in Apache TVM compiler, and generate the binary model library that enables the execution language models on your local GPU.
Phase 3. Chat runtime. This phase consumes the model library built in phase 2 and the model weights downloaded in phase 1, launches a platform-native chat runtime to drive the execution of Llama-3 model.
We cache the pre-quantized model weights and compiled model library locally. Therefore, phase 1 and 2 will only execute once over multiple runs.

Workflow in MLC LLM¶
Python API¶
In the second example, we run the Llama-3 model with the chat completion Python API of MLC LLM. You can save the code below into a Python file and run it.
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC"
engine = MLCEngine(model)
# Run chat completion in OpenAI API.
for response in engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=True,
):
for choice in response.choices:
print(choice.delta.content, end="", flush=True)
print("\n")
engine.terminate()
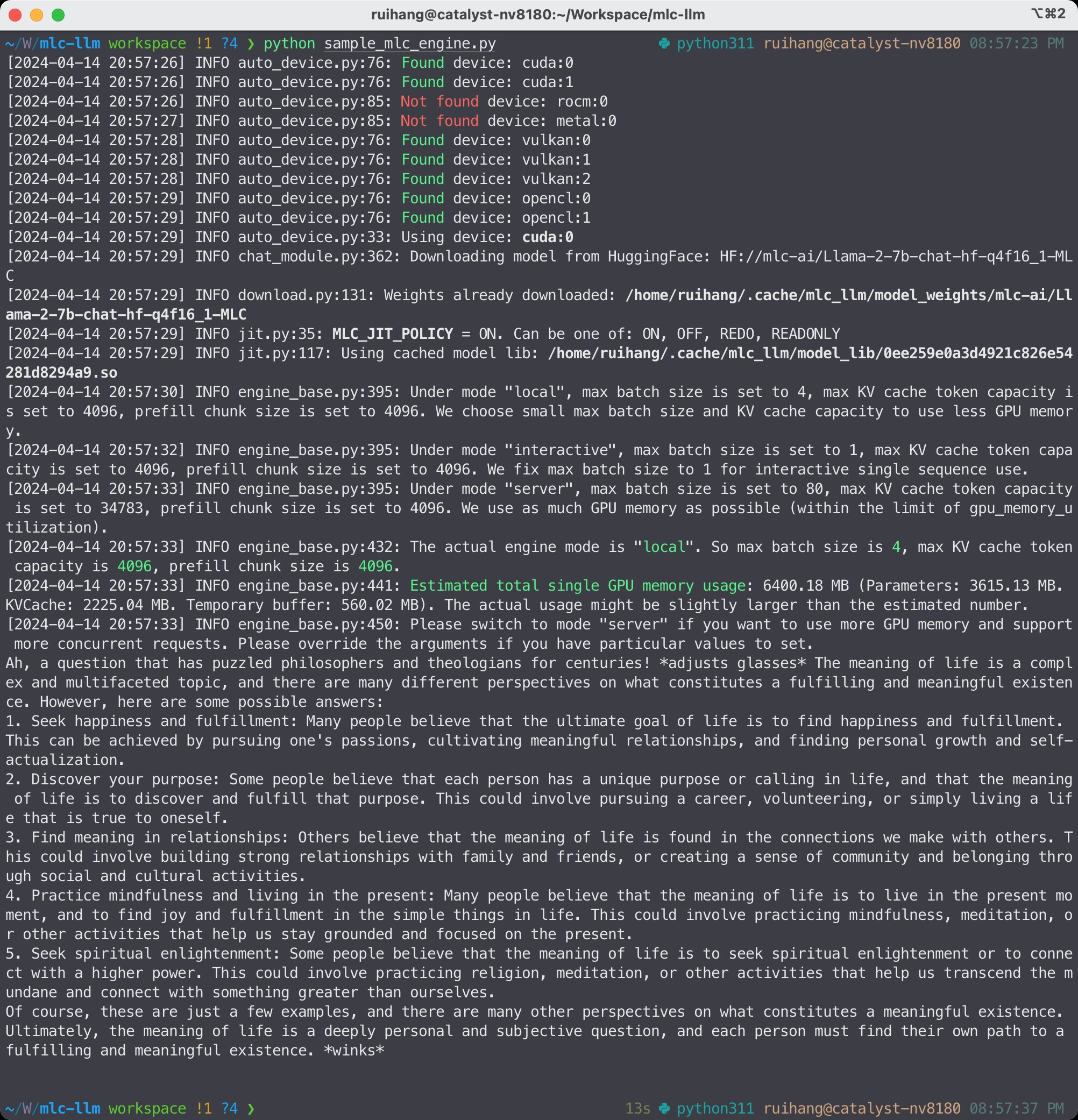
MLC LLM Python API¶
This code example first creates an mlc_llm.MLCEngine instance with the 4-bit quantized Llama-3 model.
We design the Python API mlc_llm.MLCEngine to align with OpenAI API,
which means you can use mlc_llm.MLCEngine in the same way of using
OpenAI’s Python package
for both synchronous and asynchronous generation.
In this code example, we use the synchronous chat completion interface and iterate over all the stream responses. If you want to run without streaming, you can run
response = engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=False,
)
print(response)
You can also try different arguments supported in OpenAI chat completion API.
If you would like to do concurrent asynchronous generation, you can use mlc_llm.AsyncMLCEngine instead.
REST Server¶
For the third example, we launch a REST server to serve the 4-bit quantized Llama-3 model for OpenAI chat completion requests. The server can be launched in command line with
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
The server is hooked at http://127.0.0.1:8000 by default, and you can use --host and --port
to set a different host and port.
When the server is ready (showing INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)),
we can open a new shell and send a cURL request via the following command:
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC",
"messages": [
{"role": "user", "content": "Hello! Our project is MLC LLM. What is the name of our project?"}
]
}' \
http://127.0.0.1:8000/v1/chat/completions
The server will process this request and send back the response.
Similar to Python API, you can pass argument "stream": true
to request for stream responses.
Deploy Your Own Model¶
So far we have been using pre-converted models weights from Hugging Face. This section introduces the core workflow regarding how you can run your own models with MLC LLM.
We use the Phi-2 as the example model.
Assuming the Phi-2 model is downloaded and placed under models/phi-2,
there are two major steps to prepare your own models.
Step 1. Generate MLC config. The first step is to generate the configuration file of MLC LLM.
export LOCAL_MODEL_PATH=models/phi-2 # The path where the model resides locally. export MLC_MODEL_PATH=dist/phi-2-MLC/ # The path where to place the model processed by MLC. export QUANTIZATION=q0f16 # The choice of quantization. export CONV_TEMPLATE=phi-2 # The choice of conversation template. mlc_llm gen_config $LOCAL_MODEL_PATH \ --quantization $QUANTIZATION \ --conv-template $CONV_TEMPLATE \ -o $MLC_MODEL_PATH
The config generation command takes in the local model path, the target path of MLC output, the conversation template name in MLC and the quantization name in MLC. Here the quantization
q0f16means float16 without quantization, and the conversation templatephi-2is the Phi-2 model’s template in MLC.If you want to enable tensor parallelism on multiple GPUs, add argument
--tensor-parallel-shards $NGPUto the config generation command.The full list of supported quantization in MLC. You can try different quantization methods with MLC LLM. Typical quantization methods are
q4f16_1for 4-bit group quantization,q4f16_ftfor 4-bit FasterTransformer format quantization.
Step 2. Convert model weights. In this step, we convert the model weights to MLC format.
mlc_llm convert_weight $LOCAL_MODEL_PATH \ --quantization $QUANTIZATION \ -o $MLC_MODEL_PATH
This step consumes the raw model weights and converts them to for MLC format. The converted weights will be stored under
$MLC_MODEL_PATH, which is the same directory where the config file generated in Step 1 resides.
Now, we can try to run your own model with chat CLI:
mlc_llm chat $MLC_MODEL_PATH
For the first run, model compilation will be triggered automatically to optimize the model for GPU accelerate and generate the binary model library. The chat interface will be displayed after model JIT compilation finishes. You can also use this model in Python API, MLC serve and other use scenarios.
(Optional) Compile Model Library¶
In previous sections, model libraries are compiled when the mlc_llm.MLCEngine launches,
which is what we call “JIT (Just-in-Time) model compilation”.
In some cases, it is beneficial to explicitly compile the model libraries.
We can deploy LLMs with reduced dependencies by shipping the library for deployment without going through compilation.
It will also enable advanced options such as cross-compiling the libraries for web and mobile deployments.
Below is an example command of compiling model libraries in MLC LLM:
export $MODEL_LIB=$MLC_MODEL_PATH/lib.so # ".dylib" for Intel Macs.
# ".dll" for Windows.
# ".wasm" for web.
# ".tar" for iPhone/Android.
mlc_llm compile $MLC_MODEL_PATH -o $MODEL_LIB
At runtime, we need to specify this model library path to use it. For example,
# For chat CLI
mlc_llm chat $MLC_MODEL_PATH --model-lib $MODEL_LIB
# For REST server
mlc_llm serve $MLC_MODEL_PATH --model-lib $MODEL_LIB
from mlc_llm import MLCEngine
# For Python API
model = "models/phi-2"
model_lib = "models/phi-2/lib.so"
engine = MLCEngine(model, model_lib=model_lib)
Compile Model Libraries introduces the model compilation command in detail, where you can find instructions and example commands to compile model to different hardware backends, such as WebGPU, iOS and Android.
Universal Deployment¶
MLC LLM is a high-performance universal deployment solution for large language models, to enable native deployment of any large language models with native APIs with compiler acceleration So far, we have gone through several examples running on a local GPU environment. The project supports multiple kinds of GPU backends.
You can use –device option in compilation and runtime to pick a specific GPU backend. For example, if you have an NVIDIA or AMD GPU, you can try to use the option below to run chat through the vulkan backend. Vulkan-based LLM applications run in less typical environments (e.g. SteamDeck).
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC --device vulkan
The same core LLM runtime engine powers all the backends, enabling the same model to be deployed across backends as long as they fit within the memory and computing budget of the corresponding hardware backend. We also leverage machine learning compilation to build backend-specialized optimizations to get out the best performance on the targetted backend when possible, and reuse key insights and optimizations across backends we support.
Please checkout the what to do next sections below to find out more about different deployment scenarios, such as WebGPU-based browser deployment, mobile and other settings.
Summary and What to Do Next¶
To briefly summarize this page,
We went through three examples (chat CLI, Python API, and REST server) of MLC LLM,
we introduced how to convert model weights for your own models to run with MLC LLM, and (optionally) how to compile your models.
We also discussed the universal deployment capability of MLC LLM.
Next, please feel free to check out the pages below for quick start examples and more detailed information on specific platforms
Quick start examples for Python API, chat CLI, REST server, web browser, iOS and Android.
Depending on your use case, check out our API documentation and tutorial pages:
Convert model weight to MLC format, if you want to run your own models.
Compile model libraries, if you want to deploy to web/iOS/Android or control the model optimizations.
Report any problem or ask any question: open new issues in our GitHub repo.