7. 计算图优化¶
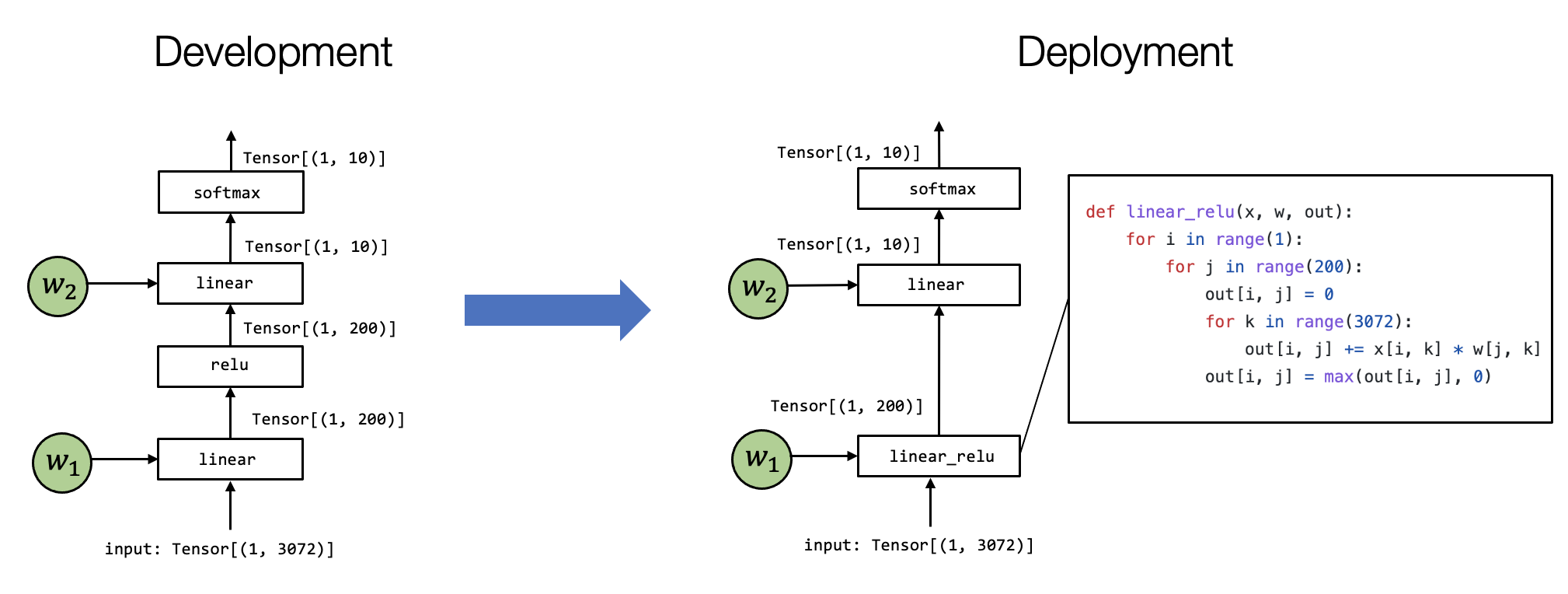
7.2. 准备工作¶
首先,让我们导入必要的依赖项。
import numpy as np
import tvm
from tvm import relax, topi
from tvm.ir.module import IRModule
from tvm.script import relax as R
from tvm.script import tir as T
7.3. 模式匹配和改写¶
首先,让我们从以下示例开始。
@tvm.script.ir_module
class MyModule:
@R.function
def main(x: R.Tensor((3, 4), "float32"), y: R.Tensor((3, 4), "float32")):
with R.dataflow():
lv0 = relax.op.multiply(x, y)
gv0 = relax.op.add(lv0, y)
R.output(gv0)
return gv0
MyModule 包含一个带有两个图层 op 的 relax 函数,其中包含
relax.op.multiply
和relax.op.add。我们的目标是找到这两个运算符并将它们替换为一个
relax.op.ewise_fma 运算符的调用。
在我们研究如何准确地做到这一点之前,让我们首先检查构成 MyModule
的数据结构。 每个 IRModule
都包含一组函数,函数体由一组称为抽象语法树(AST)的数据结构组成。
relax_func = MyModule["main"]
每个函数都由一个 relax.expr.Function 节点表示。
type(relax_func)
tvm.relax.expr.Function
该函数包含一系列参数:
relax_func.params
[x, y]
该函数包含一个返回值表达式,和函数中的一组 binding blocks 。
func_body = relax_func.body
type(func_body)
tvm.relax.expr.SeqExpr
函数主体 SeqExpr 包含一系列 binding 。
func_body.blocks
[x: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
with R.dataflow():
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y)
gv0: R.Tensor((3, 4), dtype="float32") = R.add(lv0, y)
R.output(gv0)]
dataflow_block = func_body.blocks[0]
在我们的特定情况下,我们有一个数据流块,其中包含两个 Binding 。绑定对应于以下代码:
lv0 = relax.op.multiply(x, y)
gv0 = relax.op.add(lv0, y)
dataflow_block.bindings
[x: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y), lv0: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
gv0: R.Tensor((3, 4), dtype="float32") = R.add(lv0, y)]
binding = dataflow_block.bindings[0]
每个 binding 都有一个对应于绑定左侧的 var (lv0、gv0)。
binding.var
lv0
并且每个 binding 的右侧是他的 value。 每个 value 对应一个 relax.Call
节点,表示对元函数的调用。
binding.value
R.multiply(x, y)

上图总结了这个特定函数所涉及的数据结构。
改写程序可以通过递归遍历 MyModule 的 AST ,并生成转换后的 AST 来实现。 我们当然可以直接使用构建AST的 python API 来做到这一点。 但是,我们可以使用额外的工具支持来简化流程。 下面的代码块遵循一种称为 访问者模式 (visitor pattern) 的设计模式,它允许我们访问每个 AST 节点并将它们重写为转换后的版本。
@relax.expr_functor.mutator
class EwiseFMARewriter(relax.PyExprMutator):
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
add_op = tvm.ir.Op.get("relax.add")
multiply_op = tvm.ir.Op.get("relax.multiply")
ewise_fma_op = tvm.ir.Op.get("relax.ewise_fma")
if call.op != add_op:
return call
value = self.lookup_binding(call.args[0])
if not isinstance(value, relax.Call) or value.op != multiply_op:
return call
fma_call = relax.Call(
ewise_fma_op, [value.args[0], value.args[1], call.args[1]], None, None
)
return fma_call
updated_fn = EwiseFMARewriter().visit_expr(MyModule["main"])
updated_fn.show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import relax as R
@R.function
def main(x: R.Tensor((3, 4), dtype="float32"), y: R.Tensor((3, 4), dtype="float32")) -> R.Tensor((3, 4), dtype="float32"):
with R.dataflow():
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y)
gv0: R.Tensor((3, 4), dtype="float32") = R.ewise_fma(x, y, y)
R.output(gv0)
return gv0
请注意,结果将 gv0 重写为融合运算符,但将 lv0 留在代码中。
我们可以使用 remove_all_unused 来进一步简化代码块。
relax.analysis.remove_all_unused(updated_fn).show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import relax as R
@R.function
def main(x: R.Tensor((3, 4), dtype="float32"), y: R.Tensor((3, 4), dtype="float32")) -> R.Tensor((3, 4), dtype="float32"):
with R.dataflow():
gv0: R.Tensor((3, 4), dtype="float32") = R.ewise_fma(x, y, y)
R.output(gv0)
return gv0
7.4. 融合 Linear 和 ReLU 算子¶
现在我们对计算图改写有了基本的了解,让我们在端到端模型上进行尝试。
# Hide outputs
!wget https://github.com/mlc-ai/web-data/raw/main/models/fasionmnist_mlp_params.pkl
import pickle as pkl
mlp_params = pkl.load(open("fasionmnist_mlp_params.pkl", "rb"))
以下代码重新构建了我们在过去章节中使用的 FashionMNIST MLP 模型。
为了简化过程,我们直接使用高级运算符构建模型,例如 relax.op.add 和
relax.op.matmul。
def create_model():
bb = relax.BlockBuilder()
x = relax.Var("x", relax.TensorStructInfo((1, 784), "float32"))
w0 = relax.const(mlp_params["w0"], "float32")
b0 = relax.const(mlp_params["b0"], "float32")
w1 = relax.const(mlp_params["w1"], "float32")
b1 = relax.const(mlp_params["b1"], "float32")
with bb.function("main", [x]):
with bb.dataflow():
lv0 = bb.emit(relax.op.matmul(x, relax.op.permute_dims(w0)))
lv1 = bb.emit(relax.op.add(lv0, b0))
lv2 = bb.emit(relax.op.nn.relu(lv1))
lv3 = bb.emit(relax.op.matmul(lv2, relax.op.permute_dims(w1)))
lv4 = bb.emit(relax.op.add(lv3, b1))
gv = bb.emit_output(lv4)
bb.emit_func_output(gv)
return bb.get()
MLPModel = create_model()
MLPModel.show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
with R.dataflow():
lv: R.Tensor((784, 128), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][0], axes=None)
lv1: R.Tensor((1, 128), dtype="float32") = R.matmul(x, lv, out_dtype="void")
lv2: R.Tensor((1, 128), dtype="float32") = R.add(lv1, metadata["relax.expr.Constant"][1])
lv3: R.Tensor((1, 128), dtype="float32") = R.nn.relu(lv2)
lv4: R.Tensor((128, 10), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][2], axes=None)
lv5: R.Tensor((1, 10), dtype="float32") = R.matmul(lv3, lv4, out_dtype="void")
lv6: R.Tensor((1, 10), dtype="float32") = R.add(lv5, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
我们的目标是“融合” matmul 和 add 算子到一起。
以下代码通过以下步骤实现:
识别
matmul和add算子。生成另一个调用
matmul和add算子的子函数。将
matmul和add替换为融合后的子函数。
@relax.expr_functor.mutator
class MatmulAddFusor(relax.PyExprMutator):
def __init__(self, mod: IRModule) -> None:
super().__init__()
self.mod_ = mod
# cache pre-defined ops
self.add_op = tvm.ir.Op.get("relax.add")
self.matmul_op = tvm.ir.Op.get("relax.matmul")
self.counter = 0
def transform(self) -> IRModule:
for global_var, func in self.mod_.functions.items():
if not isinstance(func, relax.Function):
continue
# avoid already fused primitive functions
if func.attrs is not None and "Primitive" in func.attrs.keys() and func.attrs["Primitive"] != 0:
continue
updated_func = self.visit_expr(func)
updated_func = relax.analysis.remove_all_unused(updated_func)
self.builder_.update_func(global_var, updated_func)
return self.builder_.get()
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
def match_call(node, op):
if not isinstance(node, relax.Call):
return False
return node.op == op
# pattern match matmul => add
if not match_call(call, self.add_op):
return call
value = self.lookup_binding(call.args[0])
if value is None:
return call
if not match_call(value, self.matmul_op):
return call
x = value.args[0]
w = value.args[1]
b = call.args[1]
# construct a new fused primitive function
param_x = relax.Var("x" ,relax.TensorStructInfo(x.struct_info.shape, x.struct_info.dtype))
param_w = relax.Var("w" ,relax.TensorStructInfo(w.struct_info.shape, w.struct_info.dtype))
param_b = relax.Var("b" ,relax.TensorStructInfo(b.struct_info.shape, b.struct_info.dtype))
bb = relax.BlockBuilder()
fn_name = "fused_matmul_add%d" % (self.counter)
self.counter += 1
with bb.function(fn_name, [param_x, param_w, param_b]):
with bb.dataflow():
lv0 = bb.emit(relax.op.matmul(param_x, param_w))
gv = bb.emit_output(relax.op.add(lv0, param_b))
bb.emit_func_output(gv)
# Add Primitive attribute to the fused funtions
fused_fn = bb.get()[fn_name].with_attr("Primitive", 1)
global_var = self.builder_.add_func(fused_fn, fn_name)
# construct call into the fused function
return relax.Call(global_var, [x, w, b], None, None)
@tvm.ir.transform.module_pass(opt_level=2, name="MatmulAddFuse")
class FuseDenseAddPass:
"""The wrapper for the LowerTensorIR pass."""
def transform_module(self, mod, ctx):
return MatmulAddFusor(mod).transform()
MLPFused = FuseDenseAddPass()(MLPModel)
MLPFused.show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def fused_matmul_add0(x: R.Tensor((1, 784), dtype="float32"), w: R.Tensor((784, 128), dtype="float32"), b: R.Tensor((128,), dtype="float32")) -> R.Tensor((1, 128), dtype="float32"):
R.func_attr({"Primitive": 1})
with R.dataflow():
lv: R.Tensor((1, 128), dtype="float32") = R.matmul(x, w, out_dtype="void")
gv: R.Tensor((1, 128), dtype="float32") = R.add(lv, b)
R.output(gv)
return gv
@R.function
def fused_matmul_add1(x: R.Tensor((1, 128), dtype="float32"), w: R.Tensor((128, 10), dtype="float32"), b: R.Tensor((10,), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"Primitive": 1})
with R.dataflow():
lv: R.Tensor((1, 10), dtype="float32") = R.matmul(x, w, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = R.add(lv, b)
R.output(gv)
return gv
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv: R.Tensor((784, 128), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][0], axes=None)
lv2: R.Tensor((1, 128), dtype="float32") = cls.fused_matmul_add0(x, lv, metadata["relax.expr.Constant"][1])
lv3: R.Tensor((1, 128), dtype="float32") = R.nn.relu(lv2)
lv4: R.Tensor((128, 10), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][2], axes=None)
lv6: R.Tensor((1, 10), dtype="float32") = cls.fused_matmul_add1(lv3, lv4, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
7.4.1. 为什么要创建子函数¶
在上面的例子中,我们创建了两个前缀为 fuse_matmul_add 的子函数。
这些子函数包含有融合后算子的计算信息。
这种重写的替代方法是简单地为融合运算符创建一个单独的原始操作(如ewise_fma)。
但是,当我们尝试融合更多运算符时,可能存在指数级数量的组合。
将融合操作分组在一起的子函数为后续的 pass
保留了原始信息,进而便于分析,无需为每个融合 pattern
引入专用的高级运算符。
7.5. 映射到 TensorIR Calls¶
融合后的 IRModule 仅包含对图层 op 的调用。 为了进一步进行底层优化和代码生成,我们需要将这些高级原语运算转换为相应的 TensorIR 函数(或调用库函数)。
以下代码将图层算子重新映射到相应的 TensorIR 函数。 在这里,我们利用
Mutator 中的内部 block builder 并使用 call_te 返回转换后的值。
@relax.expr_functor.mutator
class LowerToTensorIR(relax.PyExprMutator):
def __init__(self, mod: IRModule, op_map) -> None:
super().__init__()
self.mod_ = mod
self.op_map = {
tvm.ir.Op.get(k): v for k, v in op_map.items()
}
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
if call.op in self.op_map:
return self.op_map[call.op](self.builder_, call)
return call
def transform(self) -> IRModule:
for global_var, func in self.mod_.functions.items():
if not isinstance(func, relax.Function):
continue
updated_func = self.visit_expr(func)
self.builder_.update_func(global_var, updated_func)
return self.builder_.get()
def map_matmul(bb, call):
x, w = call.args
return bb.call_te(topi.nn.matmul, x, w)
def map_add(bb, call):
a, b = call.args
return bb.call_te(topi.add, a, b)
def map_relu(bb, call):
return bb.call_te(topi.nn.relu, call.args[0])
def map_transpose(bb, call):
return bb.call_te(topi.transpose, call.args[0], )
op_map = {
"relax.matmul": map_matmul,
"relax.add": map_add,
"relax.nn.relu": map_relu,
"relax.permute_dims": map_transpose
}
@tvm.ir.transform.module_pass(opt_level=0, name="LowerToTensorIR")
class LowerToTensorIRPass:
"""The wrapper for the LowerTensorIR pass."""
def transform_module(self, mod, ctx):
return LowerToTensorIR(mod, op_map).transform()
MLPModelTIR = LowerToTensorIRPass()(MLPFused)
MLPModelTIR.show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func
def add(rxplaceholder: T.Buffer((T.int64(1), T.int64(128)), "float32"), rxplaceholder_1: T.Buffer((T.int64(128),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(1), T.int64(128)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax0, v_ax1], rxplaceholder_1[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = rxplaceholder[v_ax0, v_ax1] + rxplaceholder_1[v_ax1]
@T.prim_func
def add1(rxplaceholder: T.Buffer((T.int64(1), T.int64(10)), "float32"), rxplaceholder_1: T.Buffer((T.int64(10),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(1), T.int64(10)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax0, v_ax1], rxplaceholder_1[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = rxplaceholder[v_ax0, v_ax1] + rxplaceholder_1[v_ax1]
@T.prim_func
def matmul(rxplaceholder: T.Buffer((T.int64(1), T.int64(784)), "float32"), rxplaceholder_1: T.Buffer((T.int64(784), T.int64(128)), "float32"), T_matmul_NN: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"layout_free_buffers": [1], "tir.noalias": True})
# with T.block("root"):
for i, j, k in T.grid(T.int64(1), T.int64(128), T.int64(784)):
with T.block("T_matmul_NN"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
T.reads(rxplaceholder[v_i, v_k], rxplaceholder_1[v_k, v_j])
T.writes(T_matmul_NN[v_i, v_j])
with T.init():
T_matmul_NN[v_i, v_j] = T.float32(0)
T_matmul_NN[v_i, v_j] = T_matmul_NN[v_i, v_j] + rxplaceholder[v_i, v_k] * rxplaceholder_1[v_k, v_j]
@T.prim_func
def matmul1(rxplaceholder: T.Buffer((T.int64(1), T.int64(128)), "float32"), rxplaceholder_1: T.Buffer((T.int64(128), T.int64(10)), "float32"), T_matmul_NN: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"layout_free_buffers": [1], "tir.noalias": True})
# with T.block("root"):
for i, j, k in T.grid(T.int64(1), T.int64(10), T.int64(128)):
with T.block("T_matmul_NN"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
T.reads(rxplaceholder[v_i, v_k], rxplaceholder_1[v_k, v_j])
T.writes(T_matmul_NN[v_i, v_j])
with T.init():
T_matmul_NN[v_i, v_j] = T.float32(0)
T_matmul_NN[v_i, v_j] = T_matmul_NN[v_i, v_j] + rxplaceholder[v_i, v_k] * rxplaceholder_1[v_k, v_j]
@T.prim_func
def relu(rxplaceholder: T.Buffer((T.int64(1), T.int64(128)), "float32"), compute: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for i0, i1 in T.grid(T.int64(1), T.int64(128)):
with T.block("compute"):
v_i0, v_i1 = T.axis.remap("SS", [i0, i1])
T.reads(rxplaceholder[v_i0, v_i1])
T.writes(compute[v_i0, v_i1])
compute[v_i0, v_i1] = T.max(rxplaceholder[v_i0, v_i1], T.float32(0))
@T.prim_func
def transpose(rxplaceholder: T.Buffer((T.int64(128), T.int64(784)), "float32"), T_transpose: T.Buffer((T.int64(784), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(784), T.int64(128)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = rxplaceholder[v_ax1, v_ax0]
@T.prim_func
def transpose1(rxplaceholder: T.Buffer((T.int64(10), T.int64(128)), "float32"), T_transpose: T.Buffer((T.int64(128), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(128), T.int64(10)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = rxplaceholder[v_ax1, v_ax0]
@R.function
def fused_matmul_add0(x: R.Tensor((1, 784), dtype="float32"), w: R.Tensor((784, 128), dtype="float32"), b: R.Tensor((128,), dtype="float32")) -> R.Tensor((1, 128), dtype="float32"):
R.func_attr({"Primitive": 1})
cls = Module
with R.dataflow():
lv = R.call_tir(cls.matmul, (x, w), out_sinfo=R.Tensor((1, 128), dtype="float32"))
gv = R.call_tir(cls.add, (lv, b), out_sinfo=R.Tensor((1, 128), dtype="float32"))
R.output(gv)
return gv
@R.function
def fused_matmul_add1(x: R.Tensor((1, 128), dtype="float32"), w: R.Tensor((128, 10), dtype="float32"), b: R.Tensor((10,), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"Primitive": 1})
cls = Module
with R.dataflow():
lv = R.call_tir(cls.matmul1, (x, w), out_sinfo=R.Tensor((1, 10), dtype="float32"))
gv = R.call_tir(cls.add1, (lv, b), out_sinfo=R.Tensor((1, 10), dtype="float32"))
R.output(gv)
return gv
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv = R.call_tir(cls.transpose, (metadata["relax.expr.Constant"][0],), out_sinfo=R.Tensor((784, 128), dtype="float32"))
lv2: R.Tensor((1, 128), dtype="float32") = cls.fused_matmul_add0(x, lv, metadata["relax.expr.Constant"][1])
lv3 = R.call_tir(cls.relu, (lv2,), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv4 = R.call_tir(cls.transpose1, (metadata["relax.expr.Constant"][2],), out_sinfo=R.Tensor((128, 10), dtype="float32"))
lv6: R.Tensor((1, 10), dtype="float32") = cls.fused_matmul_add1(lv3, lv4, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
请注意,在上面的代码中。 fused_matmul_add0 和 fused_matmul_add1
仍然是上层 relax 函数,它们调用相应的 TensorIR matmul 和 add
函数。 我们可以将它们变成一个单一的 TensorIR
函数,然后可以用于后续优化和代码生成阶段。
MLPModelFinal = relax.transform.FuseTIR()(MLPModelTIR)
MLPModelFinal.show()
/usr/share/miniconda/envs/mlc/lib/python3.8/site-packages/tvm/script/highlight.py:117: UserWarning: No module named 'black'
To print formatted TVM script, please install the formatter 'Black':
/usr/share/miniconda/envs/mlc/bin/python -m pip install "black==22.3.0" --upgrade --user
warnings.warn(
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func
def fused_matmul_add0(x: T.Buffer((T.int64(1), T.int64(784)), "float32"), w: T.Buffer((T.int64(784), T.int64(128)), "float32"), b: T.Buffer((T.int64(128),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
T_matmul_NN = T.alloc_buffer((T.int64(1), T.int64(128)))
for i, j, k in T.grid(T.int64(1), T.int64(128), T.int64(784)):
with T.block("T_matmul_NN"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
T.reads(x[v_i, v_k], w[v_k, v_j])
T.writes(T_matmul_NN[v_i, v_j])
with T.init():
T_matmul_NN[v_i, v_j] = T.float32(0)
T_matmul_NN[v_i, v_j] = T_matmul_NN[v_i, v_j] + x[v_i, v_k] * w[v_k, v_j]
for ax0, ax1 in T.grid(T.int64(1), T.int64(128)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(T_matmul_NN[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = T_matmul_NN[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func
def fused_matmul_add1(x: T.Buffer((T.int64(1), T.int64(128)), "float32"), w: T.Buffer((T.int64(128), T.int64(10)), "float32"), b: T.Buffer((T.int64(10),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
T_matmul_NN = T.alloc_buffer((T.int64(1), T.int64(10)))
for i, j, k in T.grid(T.int64(1), T.int64(10), T.int64(128)):
with T.block("T_matmul_NN"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
T.reads(x[v_i, v_k], w[v_k, v_j])
T.writes(T_matmul_NN[v_i, v_j])
with T.init():
T_matmul_NN[v_i, v_j] = T.float32(0)
T_matmul_NN[v_i, v_j] = T_matmul_NN[v_i, v_j] + x[v_i, v_k] * w[v_k, v_j]
for ax0, ax1 in T.grid(T.int64(1), T.int64(10)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(T_matmul_NN[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = T_matmul_NN[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func
def relu(rxplaceholder: T.Buffer((T.int64(1), T.int64(128)), "float32"), compute: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for i0, i1 in T.grid(T.int64(1), T.int64(128)):
with T.block("compute"):
v_i0, v_i1 = T.axis.remap("SS", [i0, i1])
T.reads(rxplaceholder[v_i0, v_i1])
T.writes(compute[v_i0, v_i1])
compute[v_i0, v_i1] = T.max(rxplaceholder[v_i0, v_i1], T.float32(0))
@T.prim_func
def transpose(rxplaceholder: T.Buffer((T.int64(128), T.int64(784)), "float32"), T_transpose: T.Buffer((T.int64(784), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(784), T.int64(128)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = rxplaceholder[v_ax1, v_ax0]
@T.prim_func
def transpose1(rxplaceholder: T.Buffer((T.int64(10), T.int64(128)), "float32"), T_transpose: T.Buffer((T.int64(128), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": True})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(128), T.int64(10)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(rxplaceholder[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = rxplaceholder[v_ax1, v_ax0]
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv = R.call_tir(cls.transpose, (metadata["relax.expr.Constant"][0],), out_sinfo=R.Tensor((784, 128), dtype="float32"))
lv2 = R.call_tir(cls.fused_matmul_add0, (x, lv, metadata["relax.expr.Constant"][1]), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv3 = R.call_tir(cls.relu, (lv2,), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv4 = R.call_tir(cls.transpose1, (metadata["relax.expr.Constant"][2],), out_sinfo=R.Tensor((128, 10), dtype="float32"))
lv6 = R.call_tir(cls.fused_matmul_add1, (lv3, lv4, metadata["relax.expr.Constant"][3]), out_sinfo=R.Tensor((1, 10), dtype="float32"))
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
7.6. 构建并运行¶
我们可以进一步,构建最终 module 并在示例图片上进行测试。
# Hide outputs
import torch
import torchvision
test_data = torchvision.datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=torchvision.transforms.ToTensor()
)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=1, shuffle=True)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
img, label = next(iter(test_loader))
img = img.reshape(1, 28, 28).numpy()
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(img[0])
plt.colorbar()
plt.grid(False)
plt.show()
print("Class:", class_names[label[0]])
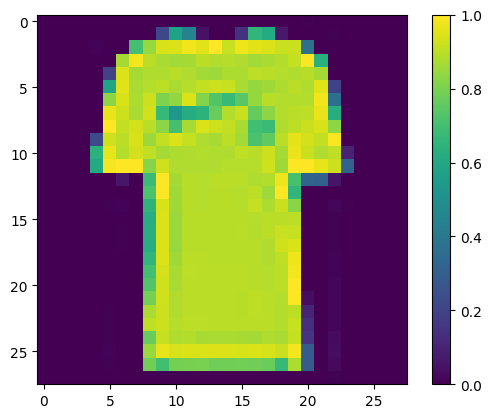
Class: T-shirt/top
ex = relax.build(MLPModelFinal, target="llvm")
vm = relax.VirtualMachine(ex, tvm.cpu())
data_nd = tvm.nd.array(img.reshape(1, 784))
nd_res = vm["main"](data_nd)
pred_kind = np.argmax(nd_res.numpy(), axis=1)
print("MLPModule Prediction:", class_names[pred_kind[0]])
MLPModule Prediction: T-shirt/top
7.7. 讨论¶
本节回到我们在计算图之间的 变换 的核心主题。 尽管上述代码是一个简单的例子,但这个转换序列涵盖了我们在 MLC 过程中通常进行的两个重要优化 —— 算子融合和循环层级的代码生成。
真实环境中的 MLC 过程可以包含更强大和更通用鲁棒的转换。 例如,如果一个
dense 的结果被两个 add 使用,本课程中的融合 pass 会复制一个
dense 算子,从而导致重复计算。 一个鲁棒的融合 pass
将检测到这一点并选择跳过此类情况。 此外,我们不想写每个算子的融合规则。
相反,TVM 内部的融合 pass 将分析 TensorIR
函数循环模式并将它们用于融合决策。
值得注意的是,这些变换可以跟其他变换随意组合。 例如,我们可以选择使用我们的自定义融合规则来支持我们想要探索的其他新融合模式,然后将其输入现有的融合器以处理其余步骤。
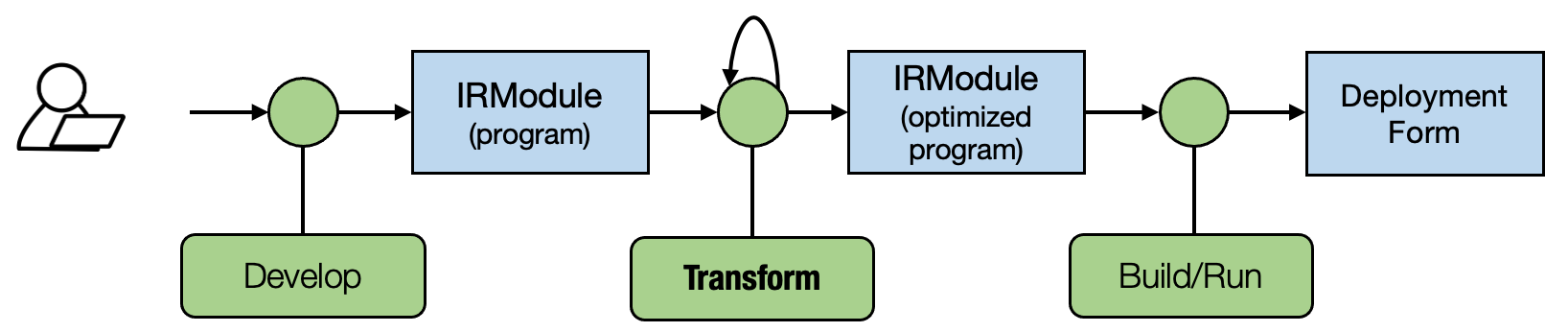
7.8. 小结¶
我们可以通过改写计算图数据结构来优化模型。
使用访问者模式改写调用节点。
我们可以进行计算图转换,例如融合和循环级代码生成。