2.4. TensorIR: 张量程序抽象案例研究¶
2.4.1. 安装相关的包¶
为了本课程的目标,我们会使用 TVM (一个开源的机器学习编译框架)中一些正在持续开发的部分。我们提供了下面的命令用于为 MLC 课程安装一个包装好的版本。
python3 -m pip install mlc-ai-nightly -f https://mlc.ai/wheels
2.4.2. 序言¶
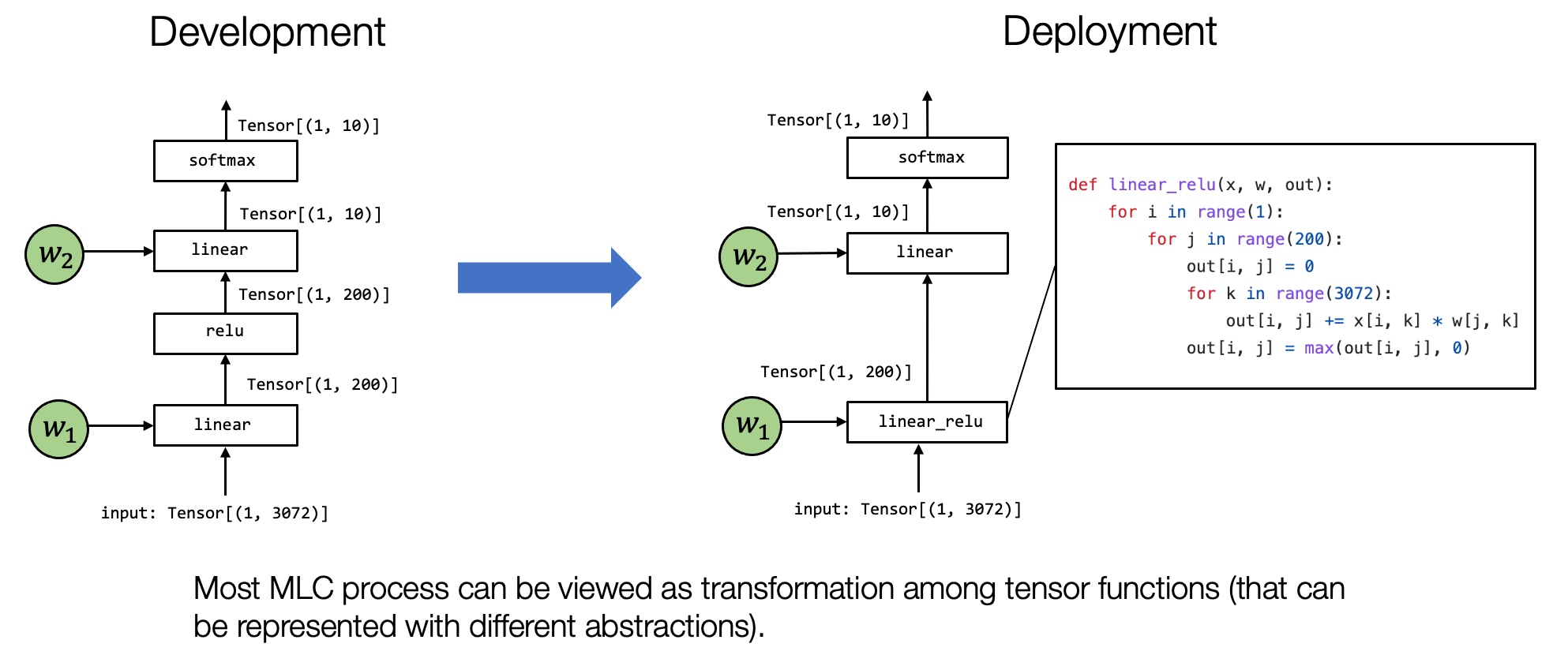
在开始今天这一节之前,让我们回忆机器学习编译过程的关键原则。大多数的机器学习编译可以被视为张量函数之间的变换。在接下来的内容中我们主要想回答的以下几个问题:
什么是表示张量函数可能的抽象?
什么是张量函数之间可能的变换?
在这里我们将聚焦于元张量函数,部分讨论这些问题。
2.4.3. 学习一类张量程序抽象 – TensorIR¶
在之前的章节中,我们介绍过了元张量函数,讨论了张量程序抽象的总体概念。
现在我们已经准备好学习一个特定的张量程序抽象的实例:TensorIR。 TensorIR 是标准机器学习编译框架 Apache TVM 中使用的张量程序抽象。
import numpy as np
import tvm
from tvm.ir.module import IRModule
from tvm.script import tir as T
使用张量程序抽象的主要目的是表示循环和相关的硬件加速选择,如多线程、特殊硬件指令的使用和内存访问。
为了帮助我们更好地解释,我们用下面的张量计算作为示例。
具体地,对于两个大小为 \(128 \times 128\) 的矩阵 A 和 B,我们进行如下两步的张量计算。
\(Y_{i, j} = \sum_k A_{i, k} \times B_{k, j}\)
\(C_{i, j} = \mathbb{relu}(Y_{i, j}) = \mathbb{max}(Y_{i, j}, 0)\)
上面的计算很像在我们神经网络中经常看到的典型的元张量函数:一个线性层与一个 ReLU 激活层。首先,我们使用如下 NumPy 中的数组计算实现这两个操作。
dtype = "float32"
a_np = np.random.rand(128, 128).astype(dtype)
b_np = np.random.rand(128, 128).astype(dtype)
# a @ b is equivalent to np.matmul(a, b)
c_mm_relu = np.maximum(a_np @ b_np, 0)
在底层,NumPy 调用库(例如 OpenBLAS)和它自己在低级 C 语言中的一些实现来执行这些计算。
从张量程序抽象的角度来看,我们想彻底理解这些数组计算的背后的细节。具体来说,我们想问:实现相应计算的可能方式是什么?
为了说明底层细节,我们将在 NumPy API 的一个受限子集中编写示例 —— 我们称之为 低级 NumPy。它使用以下的约定:
我们将在必要时使用循环而不是数组函数来展示可能的循环计算。
如果可能,我们总是通过
numpy.empty显式地分配数组并传递它们。
需要注意的是,这不是人们通常编写 NumPy
程序的方式。不过,它们仍然与幕后发生的事情非常相似 ——
大多数现实世界的部署解决方案都将分配与计算分开处理。特定的库使用不同形式的循环和算术计算来执行计算。当然首先它们是使用诸如
C 之类的低级语言实现的。
def lnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j in range(128):
for k in range(128):
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
for i in range(128):
for j in range(128):
C[i, j] = max(Y[i, j], 0)
上面的程序是实现 mm_relu
操作的一种方式。该程序包含两个阶段:首先我们分配一个中间存储
\(Y\),将矩阵乘法的结果存储在那里。然后我们在第二个 for
循环序列中计算 ReLU。你可能会注意到,这肯定不是实现 mm_relu
的唯一方法,当然这可能也不是你想到的第一件事。
无论如何,这确实是实现 mm_relu
的方式之一。我们可以通过将我们的结果与使用数组计算的原始结果进行比较来验证代码的正确性。我们将在本节的后面部分回到这里,并重新讨论其他可能的方法。
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu(a_np, b_np, c_np)
np.testing.assert_allclose(c_mm_relu, c_np, rtol=1e-5)
上面的示例代码展示了我们如何在幕后实现 mm_relu。当然,由于
Python 解释器,代码本身会运行得很慢。尽管如此,示例 NumPy
代码包含我们将在这些计算的实际实现中使用的所有可能元素。
多维缓冲区(数组)。
在数组维度上的循环。
在循环下执行的计算语句。
在看过低级 NumPy 示例后,现在我们准备介绍 TensorIR。下面的代码块展示了
mm_relu 的 TensorIR 实现。这里的代码是用一种名为 TVMScript
的语言实现的,它是一种嵌入在 Python AST 中的特定领域方言。
@tvm.script.ir_module
class MyModule:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32"),
C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
Y = T.alloc_buffer((128, 128), dtype="float32")
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
能够同时查看 NumPy 代码和 TensorIR 代码并检查相应的元素是很有帮助的。我们将详细介绍它们。

我们首先回顾一下在 NumPy 和 TensorIR 之间具有直接对应关系的元素。接下来我们将回过来查看不属于 NumPy 程序的其他元素。
2.4.3.1. 函数参数与缓冲区¶
首先,让我们看一下函数参数。函数参数对应于 NumPy 函数上的同一组参数。
# TensorIR
def mm_relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32"),
C: T.Buffer((128, 128), "float32")):
...
# numpy
def lnumpy_mm_relu(A: np.ndarray, B: np.ndarray, C: np.ndarray):
...
这里 A、B 和 C 采用名为 T.Buffer 的类型,其形状参数为
(128, 128),数据类型为
float32。这些附加信息有助于可能的机器学习编译过程以生成专门针对形状和数据类型的代码。
同样,TensorIR 在中间结果分配中也使用了缓冲区类型。
# TensorIR
Y = T.alloc_buffer((128, 128), dtype="float32")
# numpy
Y = np.empty((128, 128), dtype="float32")
2.4.3.2. For 循环迭代¶
循环迭代也有直接对应关系。T.grid 是 TensorIR
中的语法糖,供我们书写多个嵌套的迭代器。
# TensorIR
for i, j, k in T.grid(128, 128, 128):
# numpy
for i in range(128):
for j in range(128):
for k in range(128):
2.4.3.3. 计算块¶
主要区别之一来自计算语句。TensorIR 包含一个名为 T.block 的额外结构。
# TensorIR
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
# coressponding numpy code
vi, vj, vk = i, j, k
if vk == 0:
Y[vi, vj] = 0
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
块 是 TensorIR 中的基本计算单位。值得注意的是,该块包含比普通 NumPy
代码更多的信息。一个块包含一组块轴(vi、vj、vk)和围绕它们定义的计算。
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
上面三行声明了关于块轴的关键性质,语法如下。
[block_axis] = T.axis.[axis_type]([axis_range], [mapped_value])
这三行包含以下信息:
定义了
vi、vj、vk应被绑定到的位置(在本例中为i、j和k);声明了
vi、vj、vk的原始范围(T.axis.spatial(128, i)中的128);声明了块轴的属性(
spatial,reduce)。
我们一一浏览这些属性。首先,就边界关系而言,vi = T.axis.spatial(128, i)
有效地蕴含了 vi = i。[axis_range] 值提供了 [block_axis]
的预期范围。例如,vi = T.axis.spatial(128, i) 中的 128 表明
vi 应该在 range(0, 128) 中。
2.4.3.4. 块轴的属性¶
我们现在开始进一步研究块轴属性。这些轴属性标记了轴与正在执行的计算之间的关系。
下图总结了块(迭代)轴和块 Y
的读写关系。注意到,严格来说这个块正在对缓冲区 Y
进行(规约)更新,我们暂时将其标记为写入,因为我们不需要来自另一个块的缓冲区
Y 的值。
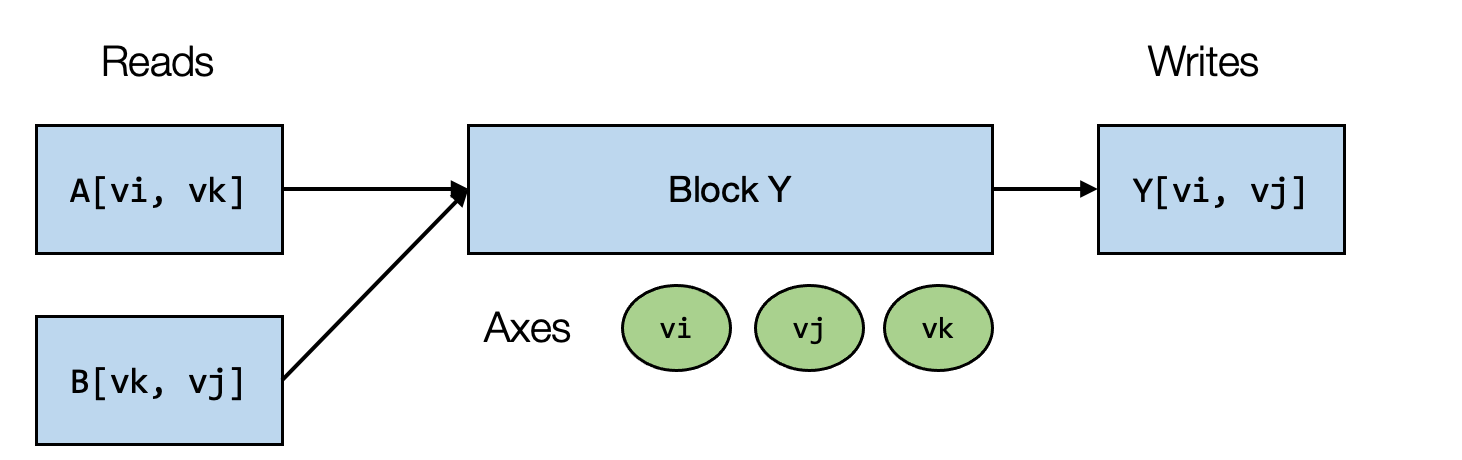
在我们的示例中,块 Y 通过读取来自 A[vi, vk] 和 B[vk, vj]
的值来计算结果 Y[vi, vj],并对所有可能的 vk 执行求和。
在这个特定示例中,如果我们将 vi、vj 固定为
(0, 1),并对 vk in range(0, 128) 执行块
Y,我们可以独立于其他可能的位置(具有不同 vi, vj
值的位置)有效地计算 C[0, 1]。
值得注意的是,对于一组固定的 vi 和 vj,计算块在 Y
的空间位置 (Y[vi, vj]) 处生成一个点值,该点值独立于 Y
中的其他位置(具有不同的vi, vj 值的位置)。我们可以称
vi、vj
为空间轴,因为它们直接对应于块写入的缓冲区空间区域的开始。
涉及归约的轴(vk)被命名为归约轴。
2.4.3.5. 为什么块需要额外附加的信息¶
一个重要的观察结果是,附加信息(块轴范围及其属性)使块轴独立于外部循环嵌套
i, j, k。
块轴信息还提供了额外的属性,帮助我们验证用于执行计算的外部循环的正确性。例如,下面的代码块会导致错误,因为循环需要一个大小为 128 的迭代器,但我们只将它绑定到一个大小为 127 的 for 循环。
# wrong program due to loop and block iteration mismatch
for i in range(127):
with T.block("C"):
vi = T.axis.spatial(128, i)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
error here due to iterator size mismatch
...
这些附加信息也有助于我们进行机器学习编译分析。例如,虽然我们总是可以在空间轴上做并行化,在规约轴上进行并行化将需要特定的策略。
2.4.3.6. 块轴绑定的语法糖¶
在每个块轴直接映射到外部循环迭代器的情况下,我们可以使用
T.axis.remap 在一行中声明所有块轴。
# SSR means the properties of each axes are "spatial", "spatial", "reduce"
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
相当于
vi = T.axis.spatial(range_of_i, i)
vj = T.axis.spatial(range_of_j, j)
vk = T.axis.reduce(range_of_k, k)
所以我们也可以编写如下程序。
@tvm.script.ir_module
class MyModuleWithAxisRemapSugar:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32"),
C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
Y = T.alloc_buffer((128, 128), dtype="float32")
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
2.4.3.7. 函数属性和装饰器¶
到目前为止,我们已经涵盖了 TensorIR 中的大部分元素。在这一部分中,我们将介绍 TVMScript 的其余元素。
函数属性信息包含关于函数的额外信息。
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
这里的 global_symbol 对应函数名,tir.noalias
是一个属性,表示所有的缓冲存储器不重叠。你现在可以放心地跳过这些属性,因为它们不会影响对概念的整体理解。
@tvm.script.ir_module 和 @T.prim_func
这两个装饰器用于表示对应部分的类型。
@tvm.script.ir_module 表示 MyModule 是一个 IRModule。IRModule
是在机器学习编译中保存张量函数集合的容器对象。
type(MyModule)
tvm.ir.module.IRModule
type(MyModule["mm_relu"])
tvm.tir.function.PrimFunc
到目前为止,我们只看到包含单个张量函数的 IRModule。 机器学习编译过程中的一个 IRModule 可以包含多个张量函数。 以下代码块显示了具有两个函数的 IRModule 示例。
@tvm.script.ir_module
class MyModuleWithTwoFunctions:
@T.prim_func
def mm(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32"),
Y: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm", "tir.noalias": True})
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
@T.prim_func
def relu(A: T.Buffer((128, 128), "float32"),
B: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "relu", "tir.noalias": True})
for i, j in T.grid(128, 128):
with T.block("B"):
vi, vj = T.axis.remap("SS", [i, j])
B[vi, vj] = T.max(A[vi, vj], T.float32(0))
2.4.3.8. 章节检查点¶
到目前为止,我们一同看过了一个 TensorIR 程序示例,并涵盖了大部分元素,包括:
参数和中间临时内存中的缓冲区声明;
For 循环迭代;
块和块轴属性。
在本节中,我们介绍了一个 TensorIR 示例,它涵盖了机器学习编译中最常见的元素。
TensorIR 包含的元素比我们在本节中介绍的更多,但本节涵盖了可以让我们开始机器学习编译之旅的大部分关键部分。我们将在后面的章节中介绍遇到的新元素。
2.4.4. 变换¶
在上一节中,我们了解了 TensorIR 及其关键元素。 现在,让我们了解所有机器学习编译工作流的主要成分——元张量函数的变换。
在上一节中,我们给出了如何使用低级 NumPy 编写 mm_relu 的示例。
在实践中,可以有多种方法来实现相同的功能,并且每种实现都可能导致不同的性能。
我们将讨论性能背后的原因以及如何在以后的内容中利用这些变体。 在本节中,让我们关注使用变换获得不同实现变体的能力。
def lnumpy_mm_relu_v2(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j0 in range(32):
for k in range(128):
for j1 in range(4):
j = j0 * 4 + j1
if k == 0:
Y[i, j] = 0
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
for i in range(128):
for j in range(128):
C[i, j] = max(Y[i, j], 0)
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu_v2(a_np, b_np, c_np)
np.testing.assert_allclose(c_mm_relu, c_np, rtol=1e-5)
上面的代码块显示了 mm_relu
的一个稍微不同的变体。它与原始程序的不同是
我们用两个循环
j0和j1替换了j循环;迭代顺序略有变化。
为了获得
lnumpy_mm_relu_v2,我们必须重写一个新函数(或手动复制粘贴和编辑)。TensorIR
引入了一个名为 Schedule 的辅助结构,它允许我们务实地做到这一点。
为了提醒我们自己,让我们再看看当前的 MyModule 内容。
import IPython
IPython.display.Code(MyModule.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
现在我们准备好尝试代码变换。我们首先创建一个以给定的 MyModule
作为输入的 Schedule 辅助类。
sch = tvm.tir.Schedule(MyModule)
然后我们执行以下操作以获得对块 Y 和相应循环的引用。
block_Y = sch.get_block("Y", func_name="mm_relu")
i, j, k = sch.get_loops(block_Y)
现在我们准备好进行变换了。我们将执行的第一个变换是将循环 j
分成两个循环,其中内部循环的长度为
4。请注意,变换是程序性的,因此如果你不小心执行了两次该代码块,我们将得到“变量
j 不再存在”的错误。如果发生这种情况,你可以从头(创建 sch
的位置)开始再次运行。
j0, j1 = sch.split(j, factors=[None, 4])
我们可以查看存储在 sch.mod 中的变换结果。
IPython.display.Code(sch.mod.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0, j_1, k in T.grid(128, 32, 4, 128):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
在变换的第一步之后,我们创建了两个新的循环,j_0 和
j_1,分别对应范围 32 和 4。下一步是重新排序这两个循环。
sch.reorder(j0, k, j1)
IPython.display.Code(sch.mod.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0, k, j_1 in T.grid(128, 32, 128, 4):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
现在重新排序后的代码非常类似于 lnumpy_mm_relu_v2。
2.4.4.1. 获得另一个变体¶
在本节中,我们将继续进行另外两步变换以得到另一个变体。首先,我们使用名为
reverse_compute_at 的原语将块 C 移动到 Y 的内循环里。
block_C = sch.get_block("C", "mm_relu")
sch.reverse_compute_at(block_C, j0)
IPython.display.Code(sch.mod.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0 in T.grid(128, 32):
for k, j_1 in T.grid(128, 4):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for ax0 in range(4):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + ax0)
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
到目前为止,我们将归约初始化和更新放在一个块体中。这种组合形式为循环变换带来了便利(因为初始化和更新的外循环
i、j 通常需要彼此保持同步)。
在循环变换之后,我们可以将 Y
元素的初始化与归约更新分开。我们可以通过 decompose_reduction
原语来做到这一点。(注意:这也是 TVM
在以后编译的时候隐式做的,所以这一步的主要目的是让它显式,看看最终效果)。
sch.decompose_reduction(block_Y, k)
IPython.display.Code(sch.mod.script(), language="python")
最终变换后的代码类似于以下低级 NumPy 代码。
def lnumpy_mm_relu_v3(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((128, 128), dtype="float32")
for i in range(128):
for j0 in range(32):
# Y_init
for j1 in range(4):
j = j0 * 4 + j1
Y[i, j] = 0
# Y_update
for k in range(128):
for j1 in range(4):
j = j0 * 4 + j1
Y[i, j] = Y[i, j] + A[i, k] * B[k, j]
# C
for j1 in range(4):
j = j0 * 4 + j1
C[i, j] = max(Y[i, j], 0)
c_np = np.empty((128, 128), dtype=dtype)
lnumpy_mm_relu_v3(a_np, b_np, c_np)
np.testing.assert_allclose(c_mm_relu, c_np, rtol=1e-5)
2.4.4.2. 章节总结与讨论¶
本节的主要内容是习惯增量代码变换的范例。在我们的特定示例中,我们使用
tir.Schedule 作为辅助工具。
重要的是,我们避免了重新创建同一程序的不同变体(lnumpy_mm_relu、lnumpy_mm_relu_v2
和 lnumpy_mm_relu_v3)的需要。
块中的附加信息(轴信息)是我们可以在后台进行此类变换的原因。
2.4.5. 构建与运行¶
到目前为止,我们只查看了变换结果的 TVMScript 输出。我们也可以运行 IRModule 中得到的程序。
首先,我们调用构建函数将 IRModule 变换为
runtime.Module,它表示可运行函数的集合。 这里 target
指定了部署环境的详细信息。对于现在这种特殊情况,我们将使用
llvm,它可以帮助我们编译到本机 CPU 平台。
当我们针对不同的平台(例如 Android 手机)或具有特殊说明的平台(Intel
Skylake)时,我们需要相应地调整
target。当我们开始部署到这些环境时,我们将讨论不同的目标选择。
rt_lib = tvm.build(MyModule, target="llvm")
然后,我们将创建三个用于保存输入和输出的 TVM NDArray。
a_nd = tvm.nd.array(a_np)
b_nd = tvm.nd.array(b_np)
c_nd = tvm.nd.empty((128, 128), dtype="float32")
type(c_nd)
tvm.runtime.ndarray.NDArray
最后,我们可以从 rt_lib
中获取可运行函数,并通过传递三个数组参数来执行它。我们可以进一步运行验证来检查代码差异。
func_mm_relu = rt_lib["mm_relu"]
func_mm_relu(a_nd, b_nd, c_nd)
np.testing.assert_allclose(c_mm_relu, c_nd.numpy(), rtol=1e-5)
我们已经构建并运行了原始的 MyModule。 我们还可以构建变换后的程序。
rt_lib_after = tvm.build(sch.mod, target="llvm")
rt_lib_after["mm_relu"](a_nd, b_nd, c_nd)
np.testing.assert_allclose(c_mm_relu, c_nd.numpy(), rtol=1e-5)
最后,我们可以比较一下两者的时间差。 time_evaluator
是一个辅助的测试函数,可用于比较不同生成函数的运行性能。
f_timer_before = rt_lib.time_evaluator("mm_relu", tvm.cpu())
print("Time cost of MyModule %g sec" % f_timer_before(a_nd, b_nd, c_nd).mean)
f_timer_after = rt_lib_after.time_evaluator("mm_relu", tvm.cpu())
print("Time cost of transformed sch.mod %g sec" % f_timer_after(a_nd, b_nd, c_nd).mean)
Time cost of MyModule 0.00214587 sec
Time cost of transformed sch.mod 0.00101764 sec
两个代码之间的运行时间差异很有意思。让我们快速分析一下影响性能的可能因素。 首先,让我们回忆原始代码的两种变体。
import IPython
IPython.display.Code(MyModule.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for i, j in T.grid(128, 128):
with T.block("C"):
vi, vj = T.axis.remap("SS", [i, j])
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
IPython.display.Code(sch.mod.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0 in T.grid(128, 32):
for k, j_1 in T.grid(128, 4):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for ax0 in range(4):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 4 + ax0)
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
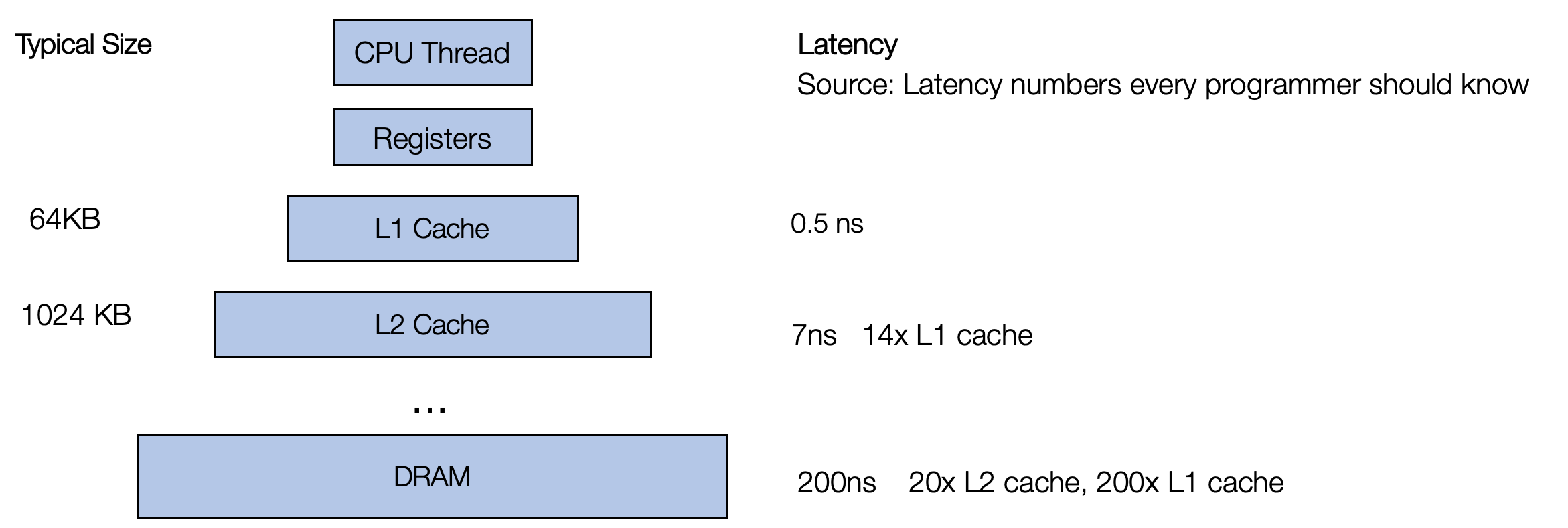
要了解为什么不同的循环变体会导致不同的性能,我们需要回顾一个事实,即访问
A 和 B 中的任何内存块的速度并不一致。现代 CPU
带有多级缓存,需要先将数据提取到缓存中,然后 CPU 才能访问它。
重要的是,访问已经在缓存中的数据要快得多。CPU 采用的一种策略是获取彼此更接近的数据。 当我们读取内存中的一个元素时,它会尝试将附近的元素(更正式的名称为“缓存行”)获取到缓存中。 因此,当你读取下一个元素时,它已经在缓存中。 因此,具有连续内存访问的代码通常比随机访问内存不同部分的代码更快。
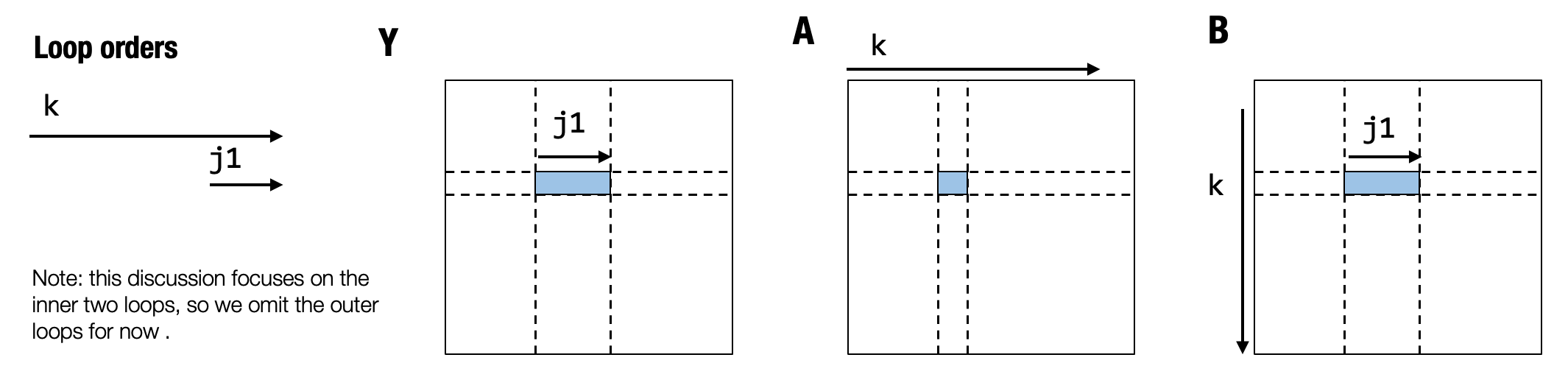
现在让我们看看上面的迭代可视化,分析一下是怎么回事。
在这个分析中,让我们关注最里面的两个循环:k 和
j1。高亮的地方显示了当我们针对 k 的一个特定实例迭代 j1
时迭代触及的 Y、A 和 B 中的相应区域。
我们可以发现,j1 这一迭代产生了对 B
元素的连续访问。具体来说,它意味着在 j1=0 和 j1=1
时我们读取的值彼此相邻。这可以让我们拥有更好的缓存访问行为。此外,我们使
C 的计算更接近 Y,从而实现更好的缓存行为。
我们当前的示例主要是为了证明不同的代码变体可以导致不同的性能。更多的变换步骤可以帮助我们获得更好的性能,我们将在以后的章节中介绍。本练习的主要目标是首先让我们获得程序变换工具,并首先体验通过变换可能实现的功能。
2.4.5.1. 练习¶
作为练习,尝试不同的 j_factor 选择,看看它们如何影响代码的性能。
def transform(mod, jfactor):
sch = tvm.tir.Schedule(mod)
block_Y = sch.get_block("Y", func_name="mm_relu")
i, j, k = sch.get_loops(block_Y)
j0, j1 = sch.split(j, factors=[None, jfactor])
sch.reorder(j0, k, j1)
block_C = sch.get_block("C", "mm_relu")
sch.reverse_compute_at(block_C, j0)
return sch.mod
mod_transformed = transform(MyModule, jfactor=8)
rt_lib_transformed = tvm.build(mod_transformed, "llvm")
f_timer_transformed = rt_lib_transformed.time_evaluator("mm_relu", tvm.cpu())
print("Time cost of transformed mod_transformed %g sec" % f_timer_transformed(a_nd, b_nd, c_nd).mean)
# display the code below
IPython.display.Code(mod_transformed.script(), language="python")
Time cost of transformed mod_transformed 0.000469933 sec
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j_0 in T.grid(128, 16):
for k, j_1 in T.grid(128, 8):
with T.block("Y"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 8 + j_1)
vk = T.axis.reduce(128, k)
T.reads(A[vi, vk], B[vk, vj])
T.writes(Y[vi, vj])
with T.init():
Y[vi, vj] = T.float32(0)
Y[vi, vj] = Y[vi, vj] + A[vi, vk] * B[vk, vj]
for ax0 in range(8):
with T.block("C"):
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j_0 * 8 + ax0)
T.reads(Y[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = T.max(Y[vi, vj], T.float32(0))
2.4.6. 创建 TensorIR 并与之交互的方法¶
在上面几节中,我们了解了 TensorIR 抽象和程序变换的方法。TensorIR 具有一个名为“块”的附加结构,可以帮助我们分析和执行代码变换。自然而然我们可能会问一个问题:创建 TensorIR 函数并与之交互的常用方法有什么?
2.4.6.1. 通过 TVMScript 创建 TensorIR¶
获取 TensorIR 函数的第一种方法是直接在 TVMScript
中编写函数,这也是我们在上一节中使用的方法。 TVMScript
还允许我们在必要时跳过某些信息部分。 例如,T.axis.remap
使我们能够缩短迭代器大小注释。
TVMScript 也是一种在变换过程中检查张量函数的有用方法。在某些情况下,一种很有帮助的做法是打印出 TVMScript,进行一些手动编辑,然后将其反馈给机器学习编译流程以调试和尝试可能的(手动)变换,然后将变换后的程序重新应用到 MLC 流程中。
2.4.6.2. 使用张量表达式生成 TensorIR 代码¶
在许多情况下,我们的开发形式是不在循环级别的更高级别的抽象。 所以另一种常见的获取 TensorIR 的方式是务实地生成相关代码。
张量表达式 (TE) 是一种特定领域的语言,它通过 API 之类的表达式描述一系列计算。
from tvm import te
A = te.placeholder((128, 128), "float32", name="A")
B = te.placeholder((128, 128), "float32", name="B")
k = te.reduce_axis((0, 128), "k")
Y = te.compute((128, 128), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name="Y")
C = te.compute((128, 128), lambda i, j: te.max(Y[i, j], 0), name="C")
这里 te.compute 采用签名 te.compute(output_shape, fcompute)。
fcompute 函数描述了对于给定的索引 (i, j) 我们要如何计算元素
Y[i, j] 的值。
lambda i, j: te.sum(A[i, k] * B[k, j], axis=k)
上面的 lambda 表达式描述了计算
\(Y_{ij} = \sum_k A_{ik} B_{kj}\)。在描述计算之后,我们可以通过传递我们感兴趣的相关参数来创建一个
TensorIR
函数。在这种特殊情况下,我们想要创建一个具有两个输入参数(A,B)和一个输出参数(C)的函数。
te_func = te.create_prim_func([A, B, C]).with_attr({"global_symbol": "mm_relu"})
MyModuleFromTE = tvm.IRModule({"mm_relu": te_func})
IPython.display.Code(MyModuleFromTE.script(), language="python")
# from tvm.script import ir as I
# from tvm.script import tir as T
@I.ir_module
class Module:
@T.prim_func
def mm_relu(A: T.Buffer((128, 128), "float32"), B: T.Buffer((128, 128), "float32"), C: T.Buffer((128, 128), "float32")):
T.func_attr({"global_symbol": "mm_relu", "tir.noalias": True})
# with T.block("root"):
Y = T.alloc_buffer((128, 128))
for i, j, k in T.grid(128, 128, 128):
with T.block("Y"):
v_i, v_j, v_k = T.axis.remap("SSR", [i, j, k])
T.reads(A[v_i, v_k], B[v_k, v_j])
T.writes(Y[v_i, v_j])
with T.init():
Y[v_i, v_j] = T.float32(0)
Y[v_i, v_j] = Y[v_i, v_j] + A[v_i, v_k] * B[v_k, v_j]
for i, j in T.grid(128, 128):
with T.block("C"):
v_i, v_j = T.axis.remap("SS", [i, j])
T.reads(Y[v_i, v_j])
T.writes(C[v_i, v_j])
C[v_i, v_j] = T.max(Y[v_i, v_j], T.float32(0))
张量表达式 API 作为一个有用的工具,帮助为给定的更高级别的输入生成 TensorIR 函数。
2.4.7. 作为变换结果的 TensorIR 函数¶
在实践中,我们还将 TensorIR 函数作为变换的结果。
当我们从两个元张量函数(mm 和
relu)开始,然后应用变换将它们“融合”成单个原始张量函数 mm_relu
时,就会发生这种情况。我们将在以后的章节中介绍详细信息。
2.4.8. 讨论¶
在本节中,让我们回顾一下到目前为止我们学到了什么。我们了解到,一个常见的机器学习编译过程遵循一系列程序变换。将 TensorIR 变换过程与低级 NumPy 参考开发过程进行比较是很有趣的。
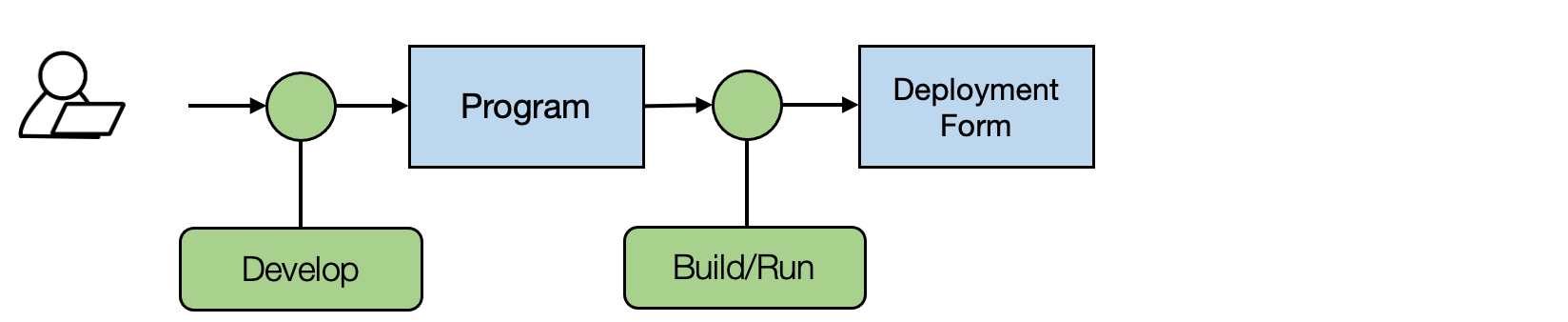
上图显示了标准的开发过程。我们需要重复开发不同程序变体的过程,然后(如果它是编译语言,则构建)在感兴趣的平台上运行它们。
机器学习编译流程(如下图所示)的主要区别在于 IRModule(程序)之间的程序变换。所以我们不仅可以通过开发(通过手动编写代码或生成代码)提出程序变体,还可以通过变换张量程序来获得变体。
变换是一个非常强大的工具,可以帮助我们简化开发成本并为流程引入更多自动化。本节介绍了通过 TensorIR 对元张量函数的特定视角,我们将在未来涵盖更多视角。
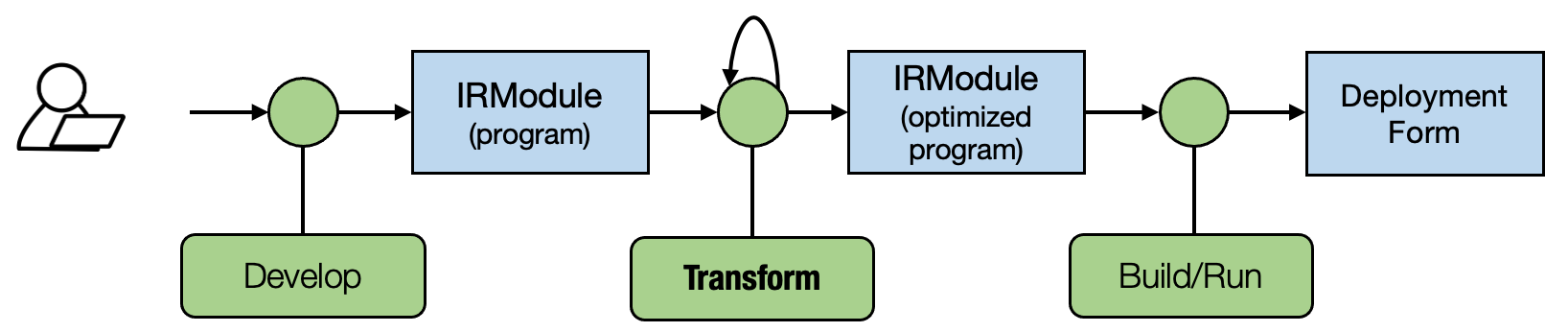
值得注意的是,直接代码开发和变换在实践中同样重要:我们仍然可以利用大量领域专业知识来开发和优化部分程序,然后将其与基于变换的方法相结合。我们将在以后的章节中讨论如何将这两种实践结合起来。
2.4.9. 总结¶
TensorIR 抽象
包含循环、多维缓冲区等常用元素
引入了一个封装循环计算要求的新结构块。
可以在 Python AST 中构建(通过 TVMScript)
我们可以使用变换来创建不同的 TensorIR 变体。
通用 MLC 流程:开发、变换、构建。