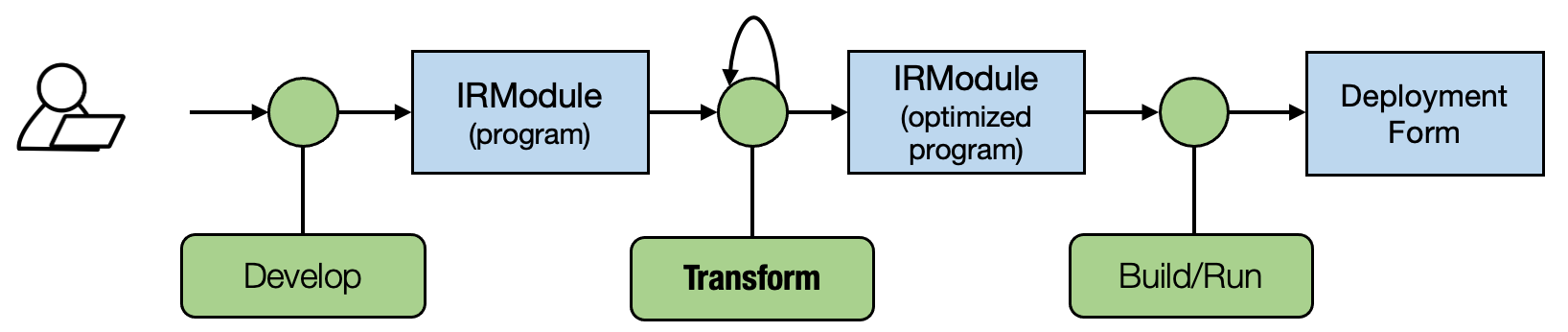
7. Computational Graph Optimization¶
7.1. Prelude¶
Most of the MLC process can be viewed as transformation among tensor functions. In the past chapters, we studied how to transform each primitive tensor functions individually. In this chapter, let us talk about high-level transformations among computational graphs.
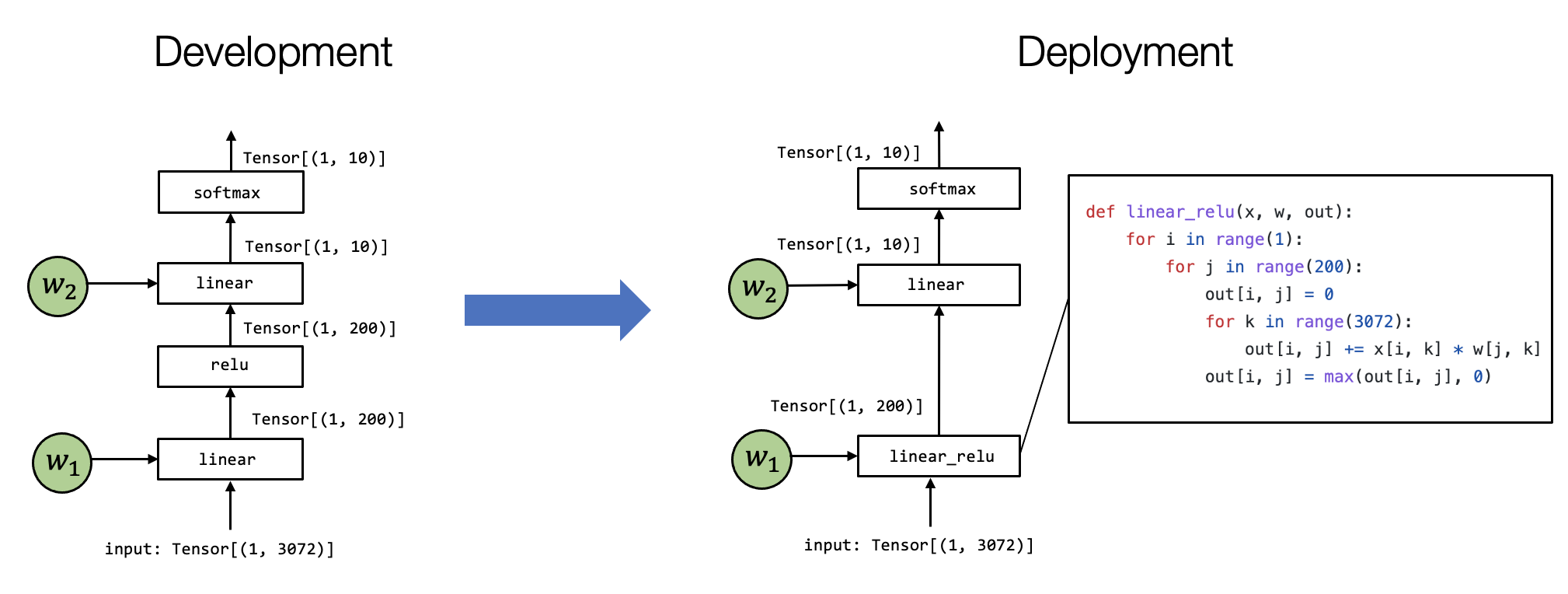
7.2. Preparations¶
To begin with, let us import the necessary dependencies.
# This is needed for deferring annotation parsing in TVMScript
import numpy as np
import tvm
from tvm import relax, topi
from tvm.ir.module import IRModule
from tvm.script import relax as R
from tvm.script import tir as T
7.3. Pattern Match and Rewriting¶
To begin with, let us start with the following example.
@tvm.script.ir_module
class MyModule:
@R.function
def main(x: R.Tensor((3, 4), "float32"), y: R.Tensor((3, 4), "float32")):
with R.dataflow():
lv0 = relax.op.multiply(x, y)
gv0 = relax.op.add(lv0, y)
R.output(gv0)
return gv0
MyModule contains a relax function with two high-level operators,
relax.op.multiply and relax.op.add. Our goal is to find these two
operators and replace it with a call into relax.op.ewise_fma
operator.
Before we dive into how to do that exactly, let us first examine the data structure that makes up the MyModule. Each IRModule contains a collection of functions, and the function body is composed of a set of data structures called abstract syntax trees (AST).
relax_func = MyModule["main"]
Each function is represented by a relax.expr.Function node.
type(relax_func)
tvm.relax.expr.Function
The function contains a list of parameters.
relax_func.params
[x, y]
The function contains a body fields that represents its return value and set of binding blocks in the function.
func_body = relax_func.body
type(func_body)
tvm.relax.expr.SeqExpr
The function body SeqExpr contains a sequence of (binding) blocks
func_body.blocks
[x: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
with R.dataflow():
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y)
gv0: R.Tensor((3, 4), dtype="float32") = R.add(lv0, y)
R.output(gv0)]
dataflow_block = func_body.blocks[0]
In our particular case, we have a single data flow block that contains two bindings. Each binding corresponds to one of the following two lines
lv0 = relax.op.multiply(x, y)
gv0 = relax.op.add(lv0, y)
dataflow_block.bindings
[x: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y), lv0: R.Tensor((3, 4), dtype="float32")
y: R.Tensor((3, 4), dtype="float32")
gv0: R.Tensor((3, 4), dtype="float32") = R.add(lv0, y)]
binding = dataflow_block.bindings[0]
Each binding have a var field that corresponds to the left hand side of
the binding (lv0, gv0).
binding.var
lv0
And its value field corresponds to the right-hand side of the binding.
Each value field corresponds to a relax.Call node representing a
call into a primitive function.
binding.value
R.multiply(x, y)

The above figure summarizes the data structure involved in this particular function.
One approach to rewrite the program would be to traverse MyModule’s AST recursively and generate a transformed AST. We can certainly do that using the python API available. However, we can use extra tooling support to simplify the process. The following code block follows a design pattern called visitor pattern that allows us to visit each AST node and rewrite them to transformed versions.
@relax.expr_functor.mutator
class EwiseFMARewriter(relax.PyExprMutator):
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
add_op = tvm.ir.Op.get("relax.add")
multiply_op = tvm.ir.Op.get("relax.multiply")
ewise_fma_op = tvm.ir.Op.get("relax.ewise_fma")
if call.op != add_op:
return call
value = self.lookup_binding(call.args[0])
if not isinstance(value, relax.Call) or value.op != multiply_op:
return call
fma_call = relax.Call(
ewise_fma_op, [value.args[0], value.args[1], call.args[1]], None, None
)
return fma_call
updated_fn = EwiseFMARewriter().visit_expr(MyModule["main"])
updated_fn.show()
# from tvm.script import relax as R
@R.function
def main(x: R.Tensor((3, 4), dtype="float32"), y: R.Tensor((3, 4), dtype="float32")) -> R.Tensor((3, 4), dtype="float32"):
with R.dataflow():
lv0: R.Tensor((3, 4), dtype="float32") = R.multiply(x, y)
gv0: R.Tensor((3, 4), dtype="float32") = R.ewise_fma(x, y, y)
R.output(gv0)
return gv0
We can go ahead and run the code. Note that the result rewrites gv0 to
the fused operator but leaves lv0 in the code. We can use
remove_all_unused to further simplify the code block.
relax.analysis.remove_all_unused(updated_fn).show()
# from tvm.script import relax as R
@R.function
def main(x: R.Tensor((3, 4), dtype="float32"), y: R.Tensor((3, 4), dtype="float32")) -> R.Tensor((3, 4), dtype="float32"):
with R.dataflow():
gv0: R.Tensor((3, 4), dtype="float32") = R.ewise_fma(x, y, y)
R.output(gv0)
return gv0
7.4. Fuse Linear and ReLU¶
Now we have get a basic taste of graph rewriting. Let us try it on an end to end model.
# Hide outputs
!wget https://github.com/mlc-ai/web-data/raw/main/models/fasionmnist_mlp_params.pkl
import pickle as pkl
mlp_params = pkl.load(open("fasionmnist_mlp_params.pkl", "rb"))
The following code reconstructs the FashionMNIST MLP model we used in
our past chapters. To simplify our explaination, we directly construct
the model using high-level operators such as relax.op.add and
relax.op.matmul.
def create_model():
bb = relax.BlockBuilder()
x = relax.Var("x", relax.TensorStructInfo((1, 784), "float32"))
w0 = relax.const(mlp_params["w0"], "float32")
b0 = relax.const(mlp_params["b0"], "float32")
w1 = relax.const(mlp_params["w1"], "float32")
b1 = relax.const(mlp_params["b1"], "float32")
with bb.function("main", [x]):
with bb.dataflow():
lv0 = bb.emit(relax.op.matmul(x, relax.op.permute_dims(w0)))
lv1 = bb.emit(relax.op.add(lv0, b0))
lv2 = bb.emit(relax.op.nn.relu(lv1))
lv3 = bb.emit(relax.op.matmul(lv2, relax.op.permute_dims(w1)))
lv4 = bb.emit(relax.op.add(lv3, b1))
gv = bb.emit_output(lv4)
bb.emit_func_output(gv)
return bb.get()
MLPModel = create_model()
MLPModel.show()
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
with R.dataflow():
lv: R.Tensor((784, 128), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][0], axes=None)
lv1: R.Tensor((1, 128), dtype="float32") = R.matmul(x, lv, out_dtype="void")
lv2: R.Tensor((1, 128), dtype="float32") = R.add(lv1, metadata["relax.expr.Constant"][1])
lv3: R.Tensor((1, 128), dtype="float32") = R.nn.relu(lv2)
lv4: R.Tensor((128, 10), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][2], axes=None)
lv5: R.Tensor((1, 10), dtype="float32") = R.matmul(lv3, lv4, out_dtype="void")
lv6: R.Tensor((1, 10), dtype="float32") = R.add(lv5, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
We aim to “fuse” the dense and add operations into a single group. The following code achieves that through the following steps:
Identify
matmulandaddpatterns.Generate another fused sub-function that calls into the matmul and add operators.
Replace
matmulandaddwith the fused sub-functions.
@relax.expr_functor.mutator
class MatmulAddFusor(relax.PyExprMutator):
def __init__(self, mod: IRModule) -> None:
super().__init__()
self.mod_ = mod
# cache pre-defined ops
self.add_op = tvm.ir.Op.get("relax.add")
self.matmul_op = tvm.ir.Op.get("relax.matmul")
self.counter = 0
def transform(self) -> IRModule:
for global_var, func in self.mod_.functions.items():
if not isinstance(func, relax.Function):
continue
# avoid already fused primitive functions
if func.attrs is not None and "Primitive" in func.attrs.keys() and func.attrs["Primitive"] != 0:
continue
updated_func = self.visit_expr(func)
updated_func = relax.analysis.remove_all_unused(updated_func)
self.builder_.update_func(global_var, updated_func)
return self.builder_.get()
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
def match_call(node, op):
if not isinstance(node, relax.Call):
return False
return node.op == op
# pattern match matmul => add
if not match_call(call, self.add_op):
return call
value = self.lookup_binding(call.args[0])
if value is None:
return call
if not match_call(value, self.matmul_op):
return call
x = value.args[0]
w = value.args[1]
b = call.args[1]
# construct a new fused primitive function
param_x = relax.Var("x" ,relax.TensorStructInfo(x.struct_info.shape, x.struct_info.dtype))
param_w = relax.Var("w" ,relax.TensorStructInfo(w.struct_info.shape, w.struct_info.dtype))
param_b = relax.Var("b" ,relax.TensorStructInfo(b.struct_info.shape, b.struct_info.dtype))
bb = relax.BlockBuilder()
fn_name = "fused_matmul_add%d" % (self.counter)
self.counter += 1
with bb.function(fn_name, [param_x, param_w, param_b]):
with bb.dataflow():
lv0 = bb.emit(relax.op.matmul(param_x, param_w))
gv = bb.emit_output(relax.op.add(lv0, param_b))
bb.emit_func_output(gv)
# Add Primitive attribute to the fused funtions
fused_fn = bb.get()[fn_name].with_attr("Primitive", 1)
global_var = self.builder_.add_func(fused_fn, fn_name)
# construct call into the fused function
return relax.Call(global_var, [x, w, b], None, None)
@tvm.ir.transform.module_pass(opt_level=2, name="MatmulAddFuse")
class FuseDenseAddPass:
"""The wrapper for the LowerTensorIR pass."""
def transform_module(self, mod, ctx):
return MatmulAddFusor(mod).transform()
MLPFused = FuseDenseAddPass()(MLPModel)
MLPFused.show()
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def fused_matmul_add0(x: R.Tensor((1, 784), dtype="float32"), w: R.Tensor((784, 128), dtype="float32"), b: R.Tensor((128,), dtype="float32")) -> R.Tensor((1, 128), dtype="float32"):
R.func_attr({"Primitive": 1})
with R.dataflow():
lv: R.Tensor((1, 128), dtype="float32") = R.matmul(x, w, out_dtype="void")
gv: R.Tensor((1, 128), dtype="float32") = R.add(lv, b)
R.output(gv)
return gv
@R.function
def fused_matmul_add1(x: R.Tensor((1, 128), dtype="float32"), w: R.Tensor((128, 10), dtype="float32"), b: R.Tensor((10,), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"Primitive": 1})
with R.dataflow():
lv: R.Tensor((1, 10), dtype="float32") = R.matmul(x, w, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = R.add(lv, b)
R.output(gv)
return gv
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv: R.Tensor((784, 128), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][0], axes=None)
lv2: R.Tensor((1, 128), dtype="float32") = cls.fused_matmul_add0(x, lv, metadata["relax.expr.Constant"][1])
lv3: R.Tensor((1, 128), dtype="float32") = R.nn.relu(lv2)
lv4: R.Tensor((128, 10), dtype="float32") = R.permute_dims(metadata["relax.expr.Constant"][2], axes=None)
lv6: R.Tensor((1, 10), dtype="float32") = cls.fused_matmul_add1(lv3, lv4, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
7.4.1. Why Creating a Sub-function¶
In the above example, we created two sub-functions with the prefix
fuse_matmul_add. These sub-function bodies contain information about
the operations performed by the fused operator. An alternative to this
rewriting is simply creating a separate primitive operation for the
fused operator (like ewise_fma). However, as we are looking into
fusing more operators, there can be an exponential amount of possible
combinations. A sub-function that groups the fused operation together
provides the same amount of information for follow-up code lowering
without introducing a dedicated high-level operator for each fusion
pattern.
7.5. Map to TensorIR Calls¶
The fused IRModule only contains calls into high-level operations. To further low-level optimization and code generation, we need to translate those high-level primitive operators into corresponding TensorIR functions (or environment library functions).
The following code remaps high-level operations to the corresponding
TensorIR functions. Here we leverage the internal block builder in each
Mutator and return the transformed value using call_te.
@relax.expr_functor.mutator
class LowerToTensorIR(relax.PyExprMutator):
def __init__(self, mod: IRModule, op_map) -> None:
super().__init__()
self.mod_ = mod
self.op_map = {
tvm.ir.Op.get(k): v for k, v in op_map.items()
}
def visit_call_(self, call):
call = self.visit_expr_post_order(call)
if call.op in self.op_map:
return self.op_map[call.op](self.builder_, call)
return call
def transform(self) -> IRModule:
for global_var, func in self.mod_.functions.items():
if not isinstance(func, relax.Function):
continue
updated_func = self.visit_expr(func)
self.builder_.update_func(global_var, updated_func)
return self.builder_.get()
def map_matmul(bb, call):
x, w = call.args
return bb.call_te(topi.nn.matmul, x, w)
def map_add(bb, call):
a, b = call.args
return bb.call_te(topi.add, a, b)
def map_relu(bb, call):
return bb.call_te(topi.nn.relu, call.args[0])
def map_transpose(bb, call):
return bb.call_te(topi.transpose, call.args[0], )
op_map = {
"relax.matmul": map_matmul,
"relax.add": map_add,
"relax.nn.relu": map_relu,
"relax.permute_dims": map_transpose
}
@tvm.ir.transform.module_pass(opt_level=0, name="LowerToTensorIR")
class LowerToTensorIRPass:
"""The wrapper for the LowerTensorIR pass."""
def transform_module(self, mod, ctx):
return LowerToTensorIR(mod, op_map).transform()
MLPModelTIR = LowerToTensorIRPass()(MLPFused)
MLPModelTIR.show()
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def add(lv: T.Buffer((T.int64(1), T.int64(128)), "float32"), b: T.Buffer((T.int64(128),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(1), T.int64(128)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(lv[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = lv[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func(private=True)
def add1(lv: T.Buffer((T.int64(1), T.int64(10)), "float32"), b: T.Buffer((T.int64(10),), "float32"), T_add: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(1), T.int64(10)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(lv[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add[v_ax0, v_ax1])
T_add[v_ax0, v_ax1] = lv[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func(private=True)
def matmul(x: T.Buffer((T.int64(1), T.int64(784)), "float32"), w: T.Buffer((T.int64(784), T.int64(128)), "float32"), T_matmul_NN: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"layout_free_buffers": [1], "tir.noalias": T.bool(True)})
# with T.block("root"):
for i0, i1, k in T.grid(T.int64(1), T.int64(128), T.int64(784)):
with T.block("T_matmul_NN"):
v_i0, v_i1, v_k = T.axis.remap("SSR", [i0, i1, k])
T.reads(x[v_i0, v_k], w[v_k, v_i1])
T.writes(T_matmul_NN[v_i0, v_i1])
with T.init():
T_matmul_NN[v_i0, v_i1] = T.float32(0.0)
T_matmul_NN[v_i0, v_i1] = T_matmul_NN[v_i0, v_i1] + x[v_i0, v_k] * w[v_k, v_i1]
@T.prim_func(private=True)
def matmul1(x: T.Buffer((T.int64(1), T.int64(128)), "float32"), w: T.Buffer((T.int64(128), T.int64(10)), "float32"), T_matmul_NN: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"layout_free_buffers": [1], "tir.noalias": T.bool(True)})
# with T.block("root"):
for i0, i1, k in T.grid(T.int64(1), T.int64(10), T.int64(128)):
with T.block("T_matmul_NN"):
v_i0, v_i1, v_k = T.axis.remap("SSR", [i0, i1, k])
T.reads(x[v_i0, v_k], w[v_k, v_i1])
T.writes(T_matmul_NN[v_i0, v_i1])
with T.init():
T_matmul_NN[v_i0, v_i1] = T.float32(0.0)
T_matmul_NN[v_i0, v_i1] = T_matmul_NN[v_i0, v_i1] + x[v_i0, v_k] * w[v_k, v_i1]
@T.prim_func(private=True)
def relu(lv2: T.Buffer((T.int64(1), T.int64(128)), "float32"), compute: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for i0, i1 in T.grid(T.int64(1), T.int64(128)):
with T.block("compute"):
v_i0, v_i1 = T.axis.remap("SS", [i0, i1])
T.reads(lv2[v_i0, v_i1])
T.writes(compute[v_i0, v_i1])
compute[v_i0, v_i1] = T.max(lv2[v_i0, v_i1], T.float32(0.0))
@T.prim_func(private=True)
def transpose(A: T.Buffer((T.int64(128), T.int64(784)), "float32"), T_transpose: T.Buffer((T.int64(784), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(784), T.int64(128)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(A[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = A[v_ax1, v_ax0]
@T.prim_func(private=True)
def transpose1(A: T.Buffer((T.int64(10), T.int64(128)), "float32"), T_transpose: T.Buffer((T.int64(128), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(128), T.int64(10)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(A[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = A[v_ax1, v_ax0]
@R.function
def fused_matmul_add0(x: R.Tensor((1, 784), dtype="float32"), w: R.Tensor((784, 128), dtype="float32"), b: R.Tensor((128,), dtype="float32")) -> R.Tensor((1, 128), dtype="float32"):
R.func_attr({"Primitive": 1})
cls = Module
with R.dataflow():
lv = R.call_tir(cls.matmul, (x, w), out_sinfo=R.Tensor((1, 128), dtype="float32"))
gv = R.call_tir(cls.add, (lv, b), out_sinfo=R.Tensor((1, 128), dtype="float32"))
R.output(gv)
return gv
@R.function
def fused_matmul_add1(x: R.Tensor((1, 128), dtype="float32"), w: R.Tensor((128, 10), dtype="float32"), b: R.Tensor((10,), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"Primitive": 1})
cls = Module
with R.dataflow():
lv = R.call_tir(cls.matmul1, (x, w), out_sinfo=R.Tensor((1, 10), dtype="float32"))
gv = R.call_tir(cls.add1, (lv, b), out_sinfo=R.Tensor((1, 10), dtype="float32"))
R.output(gv)
return gv
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv = R.call_tir(cls.transpose, (metadata["relax.expr.Constant"][0],), out_sinfo=R.Tensor((784, 128), dtype="float32"))
lv2: R.Tensor((1, 128), dtype="float32") = cls.fused_matmul_add0(x, lv, metadata["relax.expr.Constant"][1])
lv3 = R.call_tir(cls.relu, (lv2,), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv4 = R.call_tir(cls.transpose1, (metadata["relax.expr.Constant"][2],), out_sinfo=R.Tensor((128, 10), dtype="float32"))
lv6: R.Tensor((1, 10), dtype="float32") = cls.fused_matmul_add1(lv3, lv4, metadata["relax.expr.Constant"][3])
gv: R.Tensor((1, 10), dtype="float32") = lv6
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
Note that in the above code. fused_matmul_add0 and
fused_matmul_add1 still are high-level relax functions that calls
into the corresponding TensorIR matmul and add functions. We can turn
them into a single TensorIR function, which then can be used for
follow-up optimization and code generation phases.
MLPModelFinal = relax.transform.FuseTIR()(MLPModelTIR)
MLPModelFinal.show()
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
@T.prim_func(private=True)
def fused_matmul_add0(x: T.Buffer((T.int64(1), T.int64(784)), "float32"), w: T.Buffer((T.int64(784), T.int64(128)), "float32"), b: T.Buffer((T.int64(128),), "float32"), T_add_intermediate: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
T_matmul_NN_intermediate = T.alloc_buffer((T.int64(1), T.int64(128)))
for i0, i1, k in T.grid(T.int64(1), T.int64(128), T.int64(784)):
with T.block("T_matmul_NN"):
v_i0, v_i1, v_k = T.axis.remap("SSR", [i0, i1, k])
T.reads(x[v_i0, v_k], w[v_k, v_i1])
T.writes(T_matmul_NN_intermediate[v_i0, v_i1])
with T.init():
T_matmul_NN_intermediate[v_i0, v_i1] = T.float32(0.0)
T_matmul_NN_intermediate[v_i0, v_i1] = T_matmul_NN_intermediate[v_i0, v_i1] + x[v_i0, v_k] * w[v_k, v_i1]
for ax0, ax1 in T.grid(T.int64(1), T.int64(128)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(T_matmul_NN_intermediate[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add_intermediate[v_ax0, v_ax1])
T_add_intermediate[v_ax0, v_ax1] = T_matmul_NN_intermediate[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func(private=True)
def fused_matmul_add1(x: T.Buffer((T.int64(1), T.int64(128)), "float32"), w: T.Buffer((T.int64(128), T.int64(10)), "float32"), b: T.Buffer((T.int64(10),), "float32"), T_add_intermediate: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
T_matmul_NN_intermediate = T.alloc_buffer((T.int64(1), T.int64(10)))
for i0, i1, k in T.grid(T.int64(1), T.int64(10), T.int64(128)):
with T.block("T_matmul_NN"):
v_i0, v_i1, v_k = T.axis.remap("SSR", [i0, i1, k])
T.reads(x[v_i0, v_k], w[v_k, v_i1])
T.writes(T_matmul_NN_intermediate[v_i0, v_i1])
with T.init():
T_matmul_NN_intermediate[v_i0, v_i1] = T.float32(0.0)
T_matmul_NN_intermediate[v_i0, v_i1] = T_matmul_NN_intermediate[v_i0, v_i1] + x[v_i0, v_k] * w[v_k, v_i1]
for ax0, ax1 in T.grid(T.int64(1), T.int64(10)):
with T.block("T_add"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(T_matmul_NN_intermediate[v_ax0, v_ax1], b[v_ax1])
T.writes(T_add_intermediate[v_ax0, v_ax1])
T_add_intermediate[v_ax0, v_ax1] = T_matmul_NN_intermediate[v_ax0, v_ax1] + b[v_ax1]
@T.prim_func(private=True)
def relu(lv2: T.Buffer((T.int64(1), T.int64(128)), "float32"), compute: T.Buffer((T.int64(1), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for i0, i1 in T.grid(T.int64(1), T.int64(128)):
with T.block("compute"):
v_i0, v_i1 = T.axis.remap("SS", [i0, i1])
T.reads(lv2[v_i0, v_i1])
T.writes(compute[v_i0, v_i1])
compute[v_i0, v_i1] = T.max(lv2[v_i0, v_i1], T.float32(0.0))
@T.prim_func(private=True)
def transpose(A: T.Buffer((T.int64(128), T.int64(784)), "float32"), T_transpose: T.Buffer((T.int64(784), T.int64(128)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(784), T.int64(128)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(A[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = A[v_ax1, v_ax0]
@T.prim_func(private=True)
def transpose1(A: T.Buffer((T.int64(10), T.int64(128)), "float32"), T_transpose: T.Buffer((T.int64(128), T.int64(10)), "float32")):
T.func_attr({"tir.noalias": T.bool(True)})
# with T.block("root"):
for ax0, ax1 in T.grid(T.int64(128), T.int64(10)):
with T.block("T_transpose"):
v_ax0, v_ax1 = T.axis.remap("SS", [ax0, ax1])
T.reads(A[v_ax1, v_ax0])
T.writes(T_transpose[v_ax0, v_ax1])
T_transpose[v_ax0, v_ax1] = A[v_ax1, v_ax0]
@R.function
def main(x: R.Tensor((1, 784), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
cls = Module
with R.dataflow():
lv = R.call_tir(cls.transpose, (metadata["relax.expr.Constant"][0],), out_sinfo=R.Tensor((784, 128), dtype="float32"))
lv2 = R.call_tir(cls.fused_matmul_add0, (x, lv, metadata["relax.expr.Constant"][1]), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv3 = R.call_tir(cls.relu, (lv2,), out_sinfo=R.Tensor((1, 128), dtype="float32"))
lv4 = R.call_tir(cls.transpose1, (metadata["relax.expr.Constant"][2],), out_sinfo=R.Tensor((128, 10), dtype="float32"))
gv = R.call_tir(cls.fused_matmul_add1, (lv3, lv4, metadata["relax.expr.Constant"][3]), out_sinfo=R.Tensor((1, 10), dtype="float32"))
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
7.6. Build and Run¶
We can go ahead and build the final module and try it out on an example picture.
# Hide outputs
import torch
import torchvision
test_data = torchvision.datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=torchvision.transforms.ToTensor()
)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=1, shuffle=True)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
img, label = next(iter(test_loader))
img = img.reshape(1, 28, 28).numpy()
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(img[0])
plt.colorbar()
plt.grid(False)
plt.show()
print("Class:", class_names[label[0]])
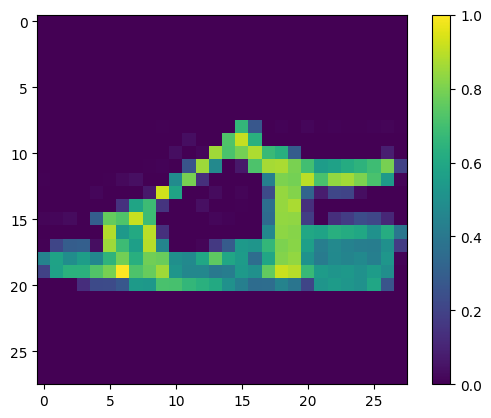
Class: Sandal
ex = relax.build(MLPModelFinal, target="llvm")
vm = relax.VirtualMachine(ex, tvm.cpu())
data_nd = tvm.nd.array(img.reshape(1, 784))
nd_res = vm["main"](data_nd)
pred_kind = np.argmax(nd_res.numpy(), axis=1)
print("MLPModule Prediction:", class_names[pred_kind[0]])
MLPModule Prediction: Sandal
7.7. Discussion¶
This section comes back to our common theme of transformation among computational graphs. Despite being minimum, this sequence of transformations covers two important optimizations we commonly do in MLC process – fusion and loop level code lowering.
Real-world MLC process can contain more powerful and robust transformations. For example, our fusion pass can create duplicated dense computations in which a dense operator is referenced in two follow-ups add operations. A robust fusion pass will detect that and choose to skip such cases. Additionally, we do not want to have to write down rules for each combination. Instead, TVM’s internal fusor will analyze the TensorIR function loop patterns and use them in fusion decisions.
Notably, each of these transformations is composable with each other. For example, we can choose to use our version of customized fusor to support additional new fusion patterns that we want to explore and then feed into an existing fusor to handle the rest of the steps.
7.8. Summary¶
We can optimize tensor programs by rewriting computational graph data structures.
Visitor pattern to rewrite call nodes.
We can perform computational graph transformations, such as fusion and loop-level program lowering.