1. Introduction¶
Machine learning applications have undoubtedly become ubiquitous. We get smart home devices powered by natural language processing and speech recognition models, computer vision models serve as backbones in autonomous driving, and recommender systems help us discover new content as we explore. Observing the rich environments where AI apps run is also quite fun. Recommender systems are usually deployed on the cloud platforms by the companies that provide the services. When we talk about autonomous driving, the natural things that pop up in our heads are powerful GPUs or specialized computing devices on vehicles. We use intelligent applications on our phones to recognize flowers in our garden and how to tend them. An increasing amount of IoT sensors also come with AI built into those tiny chips. If we drill down deeper into those environments, there are an even greater amount of diversities involved. Even for environments that belong to the same category(e.g. cloud), there are questions about the hardware(ARM or x86), operation system, container execution environment, runtime library variants, or the kind of accelerators involved. Quite some heavy liftings are needed to bring a smart machine learning model from the development phase to these production environments. Even for the environments that we are most familiar with (e.g. on GPUs), extending machine learning models to use a non-standard set of operations would involve a good amount of engineering. Many of the above examples are related to machine learning inference — the process of making predictions after obtaining model weights. We also start to see an important trend of deploying training processes themselves onto different environments. These applications come from the need to keep model updates local to users’ devices for privacy protection reasons or scaling the learning of models onto a distributed cluster of nodes. The different modeling choices and inference/training scenarios add even more complexity to the productionisation of machine learning.
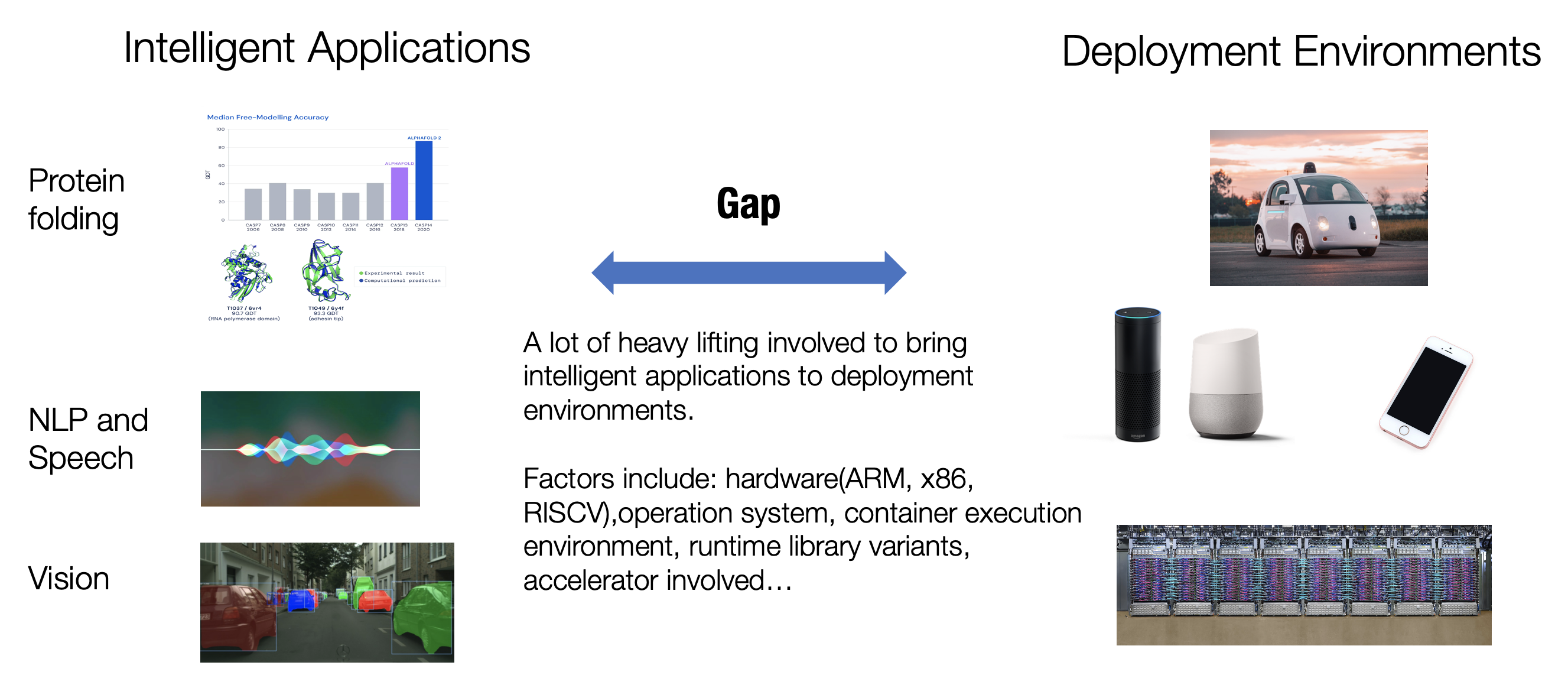
Fig. 1.1 Gap in ML deployment.¶
This course studies the topic of bringing machine learning from the development phase to production environments. We will study a collection of methods that facilitate the process of ML productionisation. Machine learning productionisation is still an open and active field, with new techniques being developed by the machine learning and systems community. Nevertheless, we start to see common themes appearing, which end up in the theme of this course.
1.1. What is ML Compilation¶
Machine learning compilation (MLC) is the process of transforming and optimizing machine learning execution from its development form to its deployment form.
Development form refers to the set of elements we use when developing machine learning models. A typical development form involves model descriptions written in common frameworks such as PyTorch, TensorFlow, or JAX, as well as weights associated with them.
Deployment form refers to the set of elements needed to execute the machine learning applications. It typically involves a set of code generated to support each step of the machine learning model, routines to manage resources (e.g. memory), and interfaces to application development environments (e.g. java API for android apps).
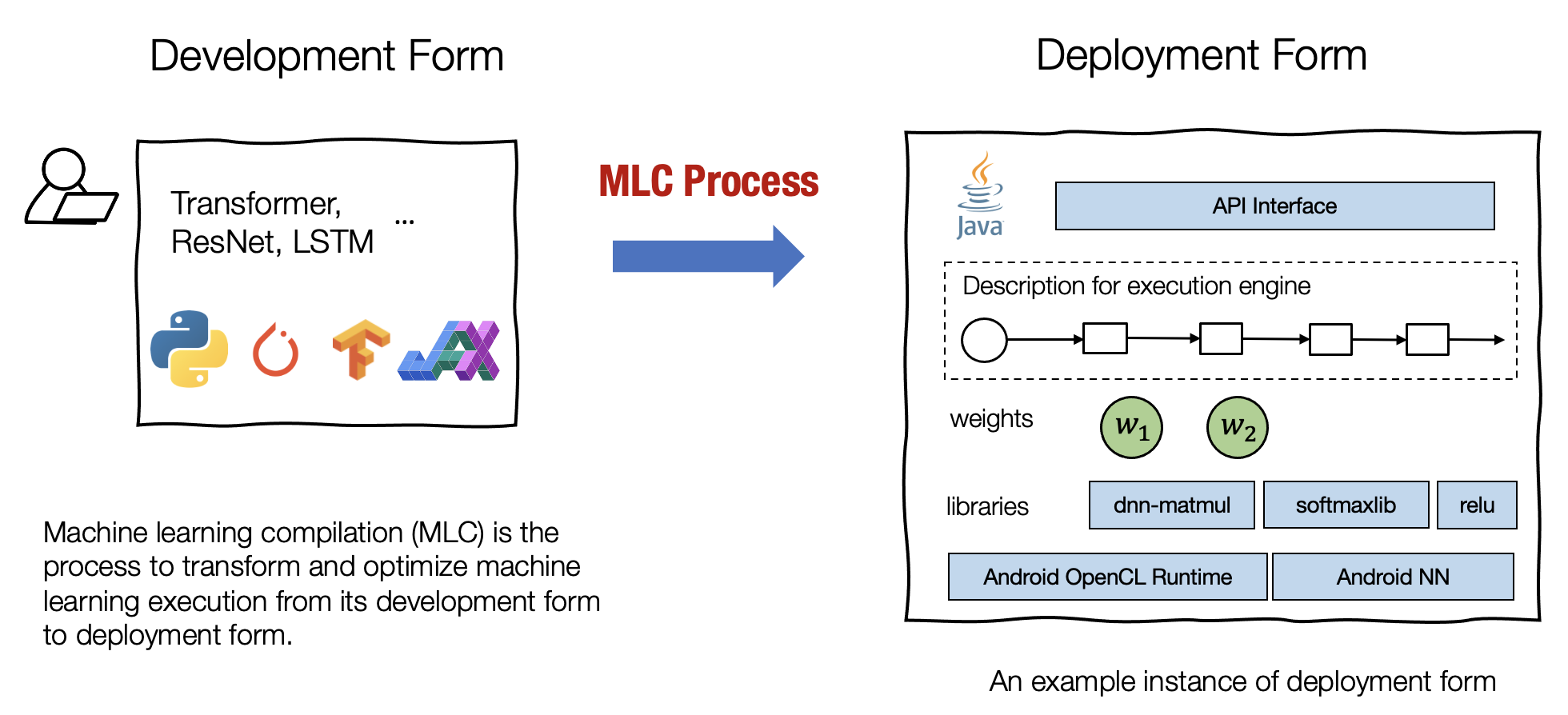
Fig. 1.1.1 Development and Deployment Forms.¶
We use the term “compilation” as the process can be viewed in close analogy to what traditional compilers do — a compiler takes our applications in development form and compiles them to libraries that can be deployed. However, machine learning compilation still differs from traditional compilation in many ways.
First of all, this process does not necessarily involve code generation. For example, the deployment form can be a set of pre-defined library functions, and the ML compilation only translates the development forms onto calls into those libraries. The set of challenges and solutions are also quite different. That is why studying machine learning compilation as its own topic is worthwhile, independent of a traditional compilation. Nevertheless, we will also find some useful traditional compilation concepts in machine learning compilation.
The machine learning compilation process usually comes with the several goals:
Integration and dependency minimization. The process of deployment usually involves integration — assembling necessary elements together for the deployment app. For example, if we want to enable an android camera app to classify flowers, we will need to assemble the necessary code that runs the flower classification models, but not necessarily other parts that are not related to the model (e.g. we do not need to include an embedding table lookup code for NLP applications). The ability to assemble and minimize the necessary dependencies is quite important to reduce the overall size and increase the possible number of environments that the app can be deployed to.
Leveraging hardware native acceleration. Each deployment environment comes with its own set of native acceleration techniques, many of which are especially developed for ML. One goal of the machine learning compilation process is to leverage that hardware’s native acceleration. We can do it through building deployment forms that invoke native acceleration libraries or generate code that leverages native instructions such as TensorCore.
Optimization in general. There are many equivalent ways to run the same model execution. The common theme of MLC is optimization in different forms to transform the model execution in ways that minimize memory usage or improve execution efficiency.
There is not a strict boundary in those goals. For example, integration and hardware acceleration can also be viewed as optimization in general. Depending on the specific application scenario, we might be interested in some pairs of source models and production environments, or we could be interested in deploying to multiple and picking the most cost-effective variants.
Importantly, MLC does not necessarily indicate a single stable solution. As a matter of fact, many MLC practices involves collaborations with developers from different background as the amount of hardware and model set grows. Hardware developers need support for their latest hardware native acceleration, machine learning engineers aim to enable additional optimizations, and scientists bring in new models.
1.2. Why Study ML Compilation¶
This course teaches machine learning compilation as a methodology and collections of tools that come along with the common methodology. These tools can work with or simply work inside common machine learning systems to provide value to the users. For machine learning engineers who are working on ML in the wild, MLC provides the bread and butter to solve problems in a principled fashion. It helps to answer questions like what methodology we can take to improve the deployment and memory efficiency of a particular model of interest and how to generalize the experience of optimizing a single part of the model to a more generic end-to-end solution. For machine learning scientists, MLC offers a more in-depth view of the steps needed to bring models into production. Some of the complexity is hidden by machine learning frameworks themselves, but challenges remain as we start to incorporate novel model customization or when we push our models to platforms that are not well supported by the frameworks. ML compilation also gives ML scientists an opportunity to understand the rationales under the hood and answer questions like why my model isn’t running as fast as expected and what can be done to make the deployment more effective. For hardware providers, MLC provides a general approach to building a machine learning software stack to best leverage the hardware they build. It also provides tools to automate the software optimizations to keep up with new generations of hardware and model developments while minimizing the overall engineering effort. Importantly, machine learning compilation techniques are not being used in isolation. Many of the MLC techniques have been applied or are being incorporated into common machine learning frameworks, and machine learning deployment flows. MLC is playing an increasingly important role in shaping the API, architectures, and connection components of the machine learning software ecosystem. Finally, learning MLC itself is fun. With the set of modern machine learning compilation tools, we can get into stages of machine learning model from high-level, code optimizations, to bare metal. It is really fun to get end to end understanding of what is happening here and use them to solve our problems.
1.3. Key Elements of ML Compilation¶

Fig. 1.3.1 MLC Elements.¶
In the previous sections, we discussed machine learning compilation at a high level. Now, let us dive deeper into some of the key elements of machine learning compilation. Let us begin by reviewing an example of two-layer neural network model execution.
In this particular model, we take a vector by flattening pixels in an
input image; then, we apply a linear transformation that projects the
input image onto a vector of length 200 with relu activation.
Finally, we map it to a vector of length 10, with each element of the
vector corresponding to how likely the image belongs to that particular
class.
Tensor is the first and foremost important element in the execution. A tensor is a multidimensional array representing the input, output, and intermediate results of a neural network model execution.
Tensor functions The neural network’s “knowledge” is encoded in the weights and the sequence of computations that takes in tensors and output tensors. We call these computations tensor functions. Notably, a tensor function does not need to correspond to a single step of neural network computation. Part of the computation or entire end-to-end computation can also be seen as a tensor function.
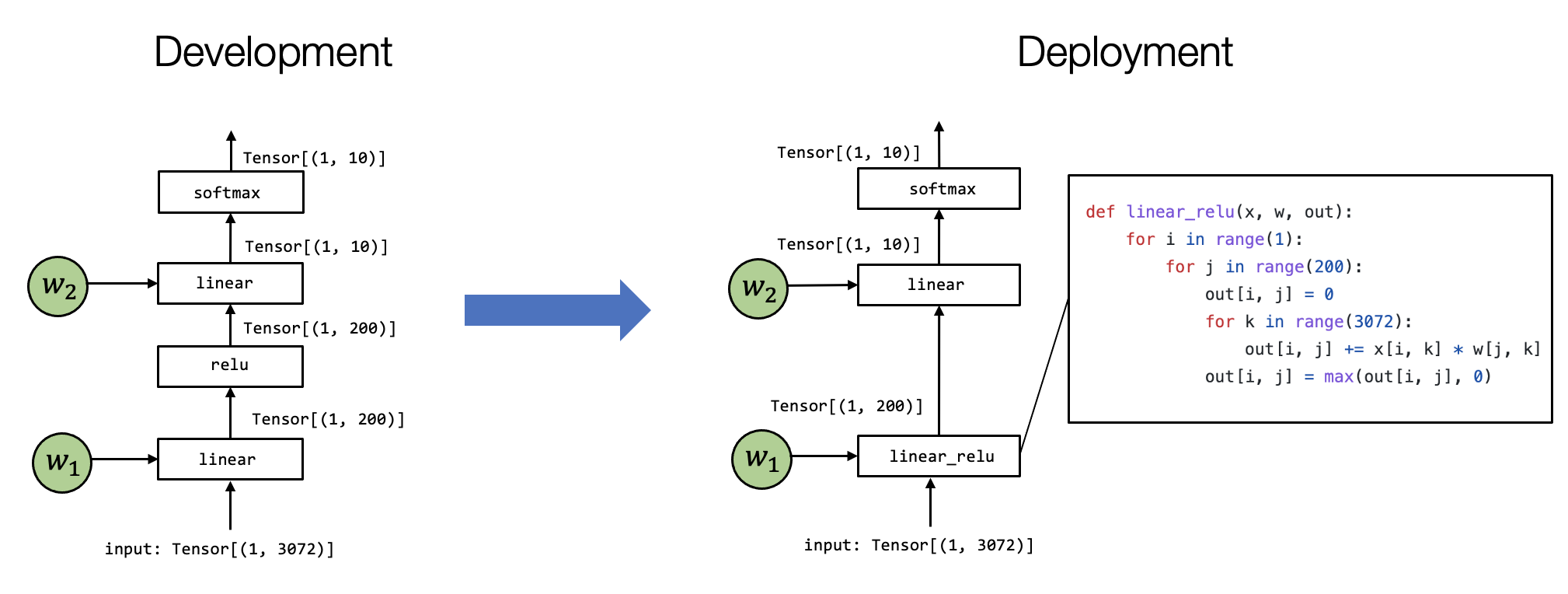
Fig. 1.3.2 Example MLC Process as Tensor Function Transformations.¶
There are multiple ways to implement the model execution in a particular
environment of interest. The above examples show one example. Notably,
there are two differences: First, the first linear and relu computation
are folded into a linear_relu function. There is now a detailed
implementation of the particular linear_relu. Of course, the real-world
use cases, the linear_relu will be implemented using all kinds of
code optimization techniques, some of which will be covered in the later
part of the lecture. MLC is a process of transforming something on the
left to the right-hand side. In different settings, this might be done
by hand, with some automatic translation tools, or both.
1.3.1. Remark: Abstraction and Implementations¶
One thing that we might notice is that we use several different ways to
represent a tensor function. For example, linear_relu is shown that
it can be represented as a compact box in a graph or a loop nest
representation.

Fig. 1.3.3 Abstractions and Implementations.¶
We use abstractions to denote the ways we use to represent the same
tensor function. Different abstractions may specify some details while
leaving out other implementation details. For example,
linear_relu can be implemented using another different for loops.
Abstraction and implementation are perhaps the most important keywords in all computer systems. An abstraction specifies “what” to do, and implementation provides “how” to do it. There are no specific boundaries. Depending on how we see it, the for loop itself can be viewed as an abstraction since it can be implemented using a python interpreter or compiled to a native assembly code.
MLC is effectively a process of transforming and assembling tensor functions under the same or different abstractions. We will study different kinds of abstractions for tensor functions and how they can work together to solve the challenges in machine learning deployment.
1.4. Summary¶
Goals of machine learning compilation
Integration and dependency minimization
Leveraging hardware native acceleration
Optimization in general
Why study ML compilation
Build ML deployment solutions.
In-depth view of existing ML frameworks.
Build up software stack for emerging hardware.
Key elements of ML compilation
Tensor and tensor functions.
Abstraction and implementation are useful tools to think