Data Layout and Its Notation#
Overview
A data layout maps a tensor’s logical indices to physical locations. This mapping determines not only whether the program reads the correct data, but also whether global-memory accesses coalesce, whether shared-memory accesses encounter bank conflicts, and whether a tile has the format required by a particular hardware unit.
The Shape-Stride model defines this mapping with a shape and a set of strides. Tiling uses the same model after splitting the original indices into more coordinates. Named axes extend physical locations to TMEM, warp lanes, and registers, while replication and offset represent data copies and fixed translations.
A swizzle rearranges shared-memory addresses without changing the logical shape of a tile. For a matching element width, alignment, and access pattern, an XOR swizzle can distribute accesses across memory banks and avoid bank conflicts.
Computations over the same values can differ in performance by an order of magnitude on the same GPU depending only on how those values are physically arranged in memory.
A tensor’s logical indices do not say where its bytes are actually stored. The hardware is highly sensitive to that placement. It determines whether loads from 32 lanes coalesce into one transaction or split across as many as 32, whether addresses land in different memory banks or collide and serialize, and whether a tile has a byte arrangement that a Tensor Core can read.
Machine learning programs usually describe a tensor by its logical shape. A data layout supplies
the missing physical information: it says where the element at logical index (i, j, …) resides,
whether in memory, in a register, or in another hardware storage space.
We begin with the Shape-Stride model and then extend the same notation to TMEM, register fragments, and multi-GPU layouts. The chapter ends with swizzling, which rearranges addresses to improve both row-wise and column-wise access to the same tile.
The Shape-Stride Model#
Before introducing GPU-specific layouts, we start with the Shape-Stride model. A shape gives the
size of each tensor dimension. The corresponding strides say how many physical elements to move
when a logical index increases by one along each dimension. We write the pair as
S[(shape) : (strides)]. The physical position of a logical index is the dot product of the index
and the strides. For example, a row-major 4×4 matrix is:
S[(4, 4) : (4, 1)]
addr(i, j) = i·4 + j·1
PyTorch and NumPy tensors already use this model: a flat storage buffer together with shape and
strides metadata that describes how to interpret the storage.
import torch
t = torch.arange(12).reshape(3, 4)
t.shape # torch.Size([3, 4])
t.stride() # (4, 1) ← exactly S[(3, 4) : (4, 1)]
The underlying storage of t remains one-dimensional:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Here, t uses S[(3, 4) : (4, 1)]: each row occupies four consecutive elements, and adjacent
columns are adjacent in storage. Many view-producing operations need only change the shape and
strides; they do not rearrange the elements. For a two-dimensional tensor, for example,
permute(1, 0) is equivalent to t.T:
tt = t.permute(1, 0) # or t.T
tt.shape # torch.Size([4, 3])
tt.stride() # (1, 4) ← strides swapped, no data moved
tt.untyped_storage().data_ptr() == t.untyped_storage().data_ptr()
# True, still the same underlying storage
The transposed view uses S[(4, 3) : (1, 4)], so the address offset of tt[i, j] is
i·1 + j·4, exactly the location of t[j, i]. Calling view on a contiguous tensor, or calling
reshape when the existing layout is compatible, works the same way. NumPy follows the same model,
except that its .strides are measured in bytes rather than elements.
Tile Layout#
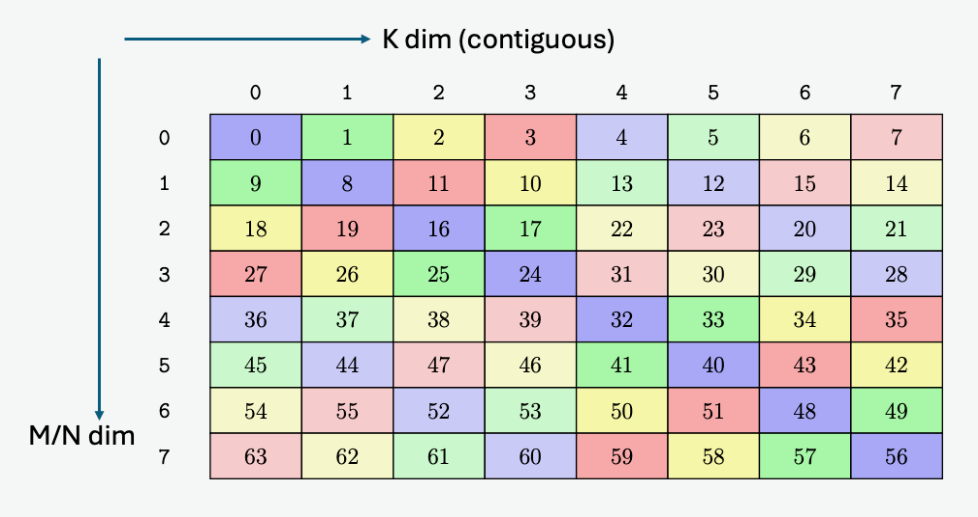
GPU kernels rarely process a full matrix at once. They usually divide it into smaller tiles. For
example, we can divide an 8×8 matrix into 2×4 tiles, store the tiles in row-major order, and also
store the elements within each tile in row-major order.
The figure below first shows this arrangement in the logical matrix and in physical memory.
Expressing Tiling as a Layout Function#
Describing the arrangement above requires both the tile’s position in the matrix and the element’s
position within that tile. Start with logical matrix coordinates (i, j) and flatten them according
to the original 8×8 shape:
x = i·8 + j
After dividing the matrix into 2×4 tiles, the row coordinate splits into four tile rows and two
rows within each tile. The column coordinate splits into two tile columns and four columns within
each tile. The shape used to decompose x is therefore:
(4, 2, 2, 4)
The layout unflattens x according to this shape:
(c0, c1, c2, c3) = unflatten(x; 4, 2, 2, 4)
c0 = x // 16
c1 = (x // 8) % 2
c2 = (x // 4) % 2
c3 = x % 4
Substituting x = i·8 + j gives:
c0 = i // 2 = tile_row
c1 = i % 2 = row_in_tile
c2 = j // 4 = tile_col
c3 = j % 4 = col_in_tile
We next map these four coordinates to a physical address. Each tile contains 2×4=8 elements, each
tile row contains two tiles, and each row within a tile contains four contiguous elements. Therefore:
The resulting layout is:
S[(4, 2, 2, 4) : (16, 4, 8, 1)]
Click any cell in the figure above to compare its tile coordinates and physical address with the unflattening process and \(f_D(x)\).
The General Layout Function#
The same calculation extends to a general Shape-Stride layout:
S[(e0, e1, ..., en-1) : (s0, s1, ..., sn-1)]
For a flat logical index \(x\), first unflatten it according to the shape:
Then take the dot product of those coordinates and the strides:
The shape determines how \(x\) is decomposed into coordinates, while the strides determine how those
coordinates map to a physical location. The tile layout above is the result of choosing shape
(4, 2, 2, 4) and strides (16, 4, 8, 1).
Named Axes: From Linear Addresses to Physical Coordinates#
The layouts above map every element to a linear memory address. Some GPU storage spaces, however, require more than one coordinate to identify a physical location. TMEM and register fragments are two direct examples.
The Two-Dimensional TMEM Address Space#
Blackwell TMEM is inherently two-dimensional. Each CTA has 128 lane rows and up to 512 32-bit columns. A position in TMEM therefore requires both a lane coordinate and a column coordinate.

A single linear memory axis cannot distinguish these dimensions. We use @TLane and @TCol for the
TMEM lane and column axes. A 128×256 accumulator tile, for example, can be written as:
S[(128, 256) : (1@TLane, 1@TCol)]
(row, col) = unflatten(x; 128, 256)
f_D(x) = row@TLane + col@TCol
Here, \(f_D(x)\) no longer returns one integer address. It returns both TLane=row and TCol=col.
Ordinary linear memory, by contrast, has one address axis, @m. Making that tag explicit, a
row-major 8×16 memory tile is:
S[(8, 16) : (16@m, 1@m)]
(row, col) = unflatten(x; 8, 16)
f_D(x) = (row·16 + col)@m
Register Fragment#
Named axes also arise in the register fragments used by Tensor Cores. Consider an m8n8-style
fragment. Logically, it contains an 8×8 tile with 64 elements. Physically, those elements are
distributed across the 32 lanes of a warp, so each lane holds two fragment slots.
A lane ID alone is therefore not enough to identify an element. Its physical location has two parts: which lane owns it and which fragment slot it occupies within that lane. For this layout:
laneid = row·4 + col//2
reg = col%2
The figure below shows how the 8×8 tile is distributed across warp lanes and registers.
Click cell 43 at row r5, column c3 in the Logical 8×8 Matrix on the left. The figure shows that
logical element (5, 3) is owned by lane 21 and occupies fragment slot 1 in that lane.
We represent these two coordinates with @laneid and @reg. The @laneid axis is the lane ID
within a warp; @reg is the fragment slot local to that lane. Here, @reg is a lane-local
coordinate in the layout. A specific instruction may still pack multiple low-precision elements
into one 32-bit hardware register.
The 8×8 tile can be written as:
S[(8, 4, 2) : (4@laneid, 1@laneid, 1@reg)]
(c0, c1, c2) = unflatten(x; 8, 4, 2)
= (row, col//2, col%2)
f_D(x) = (c0·4 + c1)@laneid + c2@reg
Replication and Offset#
Broadcasting Scale Factors Across Warps in TMEM#
Block-scaled MMA is not a specific data type. It is a family of low-precision MMA operations that use per-block scale factors. Common Blackwell formats include MXFP8 and NVFP4. For the local block scaling discussed here, MXFP8 shares one E8M0 scale factor across every 32 elements along K, while NVFP4 shares one E4M3 scale factor across every 16 E2M1 FP4 elements.
The underlying idea is the same in either case: divide A and B along K into scale blocks and assign
one scale factor to each block. If each scale block contains K_blk elements along K, the block
containing element k is:
sfk = k // K_blk
Mathematically, block-scaled MMA is equivalent to scaling the A and B elements by their corresponding scale factors before performing the matrix multiply-accumulate:
A_real[m, k] = A_low[m, k] · SFA[m, k // K_blk]
B_real[k, n] = B_low[k, n] · SFB[n, k // K_blk]
D = C + A_real × B_real
SFA[m, sfk] is the scale factor for row m of A and K-scale block sfk; SFB[n, sfk] is the
corresponding factor for column n of B.
The following NVFP4 SFA example shows how these scale factors are placed in TMEM. It uses
M = 128 and SF_K = 4. Each scale factor occupies one byte, so the logical 128×4 SFA contains:
128 rows × 4 bytes/row = 512 bytes
The tcgen05.cp.32x128b.warpx4 instruction that moves this data has a .32x128b base shape:
32 local lanes, with 128 bits, or 16 bytes, per lane. Its base tile therefore also contains:
32 local lanes × 16 bytes/lane = 512 bytes
The sizes match exactly. The base tile has only 32 lane positions, however, so the 128 values of
m cannot each occupy a separate lane. Instead, split m into:
local_lane = m % 32
Mgroup = m // 32
local_lane selects one of the 32 lanes, while Mgroup selects a TCol on that lane. For a fixed
local lane l, the four groups of SFA rows are placed side by side:
TCol 0: SFA[l, 0:4]
TCol 1: SFA[l + 32, 0:4]
TCol 2: SFA[l + 64, 0:4]
TCol 3: SFA[l + 96, 0:4]
Each SFA row contains four one-byte scale factors, exactly filling one 32-bit TCol cell. The
sfk = 0…3 coordinate selects a byte within that cell. The complete packing rule is therefore:
local_lane = m % 32
Mgroup = m // 32
TCol = Mgroup
byte = sfk
byte_offset = TCol·4 + byte
For example, SFA[64, 2] has local_lane = 0 and Mgroup = 2, so it occupies byte 2 of TCol 2
on local lane 0. SFA[0, 2], SFA[32, 2], SFA[64, 2], and SFA[96, 2] all use local lane 0,
but occupy TCols 0, 1, 2, and 3 respectively. They do not share a TMEM cell.
At this point, one complete 128×4 SFA has been packed into a 32-lane base tile. A block-scaled
tcgen05.mma reads TMEM through four 32-lane partitions and expects every partition to provide
the complete scale-factor tile at the same local-lane, TCol, and byte positions. The
PTX ISA
therefore requires both SFA and SFB to be duplicated across all four partitions:
partition 0: TLane 0…31
partition 1: TLane 32…63
partition 2: TLane 64…95
partition 3: TLane 96…127
The .warpx4 qualifier multicasts the packed base tile into those four partitions. If p = 0…3
is the partition index, the physical Lane coordinate is:
TLane = local_lane + 32·p
The TCol and byte coordinates remain unchanged. SFA[64, 2] therefore appears at
(TLane, TCol, byte) coordinates (0,2,2), (32,2,2), (64,2,2), and (96,2,2).
Two unrelated groups of four appear here. The four Mgroup values pack the 128 logical m rows
along TCol. The four partitions are physical copies of that packed tile along TLane. The
interactive figure shows both directions.
SFB follows the same hardware rule, with B’s column index n replacing A’s row index m. For
example, when N = 128 and SF_K = 4, its base packing uses local_lane = n % 32,
TCol = n // 32, and byte = sfk; .warpx4 then copies it into all four 32-lane partitions.
Representing Multiple Physical Locations with Replication#
The function \(f_D(x)\) defined above returns only one location for logical element \(x\); it cannot
represent the additional copies created by .warpx4. We therefore append R[shape : strides] to
the base layout. For example, R[n : s@axis] introduces an independent replica coordinate
r = 0…n-1 and produces an offset of r·s@axis.
For the TMEM example, the four copies along the TLane axis are:
S[(32, …) : (1@TLane, …)] + R[4 : 32@TLane]
In R[4 : 32@TLane], r takes the values 0, 1, 2, and 3, producing TLane offsets of
0, 32, 64, and 96. The replication term does not add new logical data; it records the
physical locations of the copies.
The figure below shows how SFA is packed into one 32-lane base tile and how .warpx4 copies that
tile into the four TMEM partitions.
Click any SFA cell to inspect its position in the 32-lane base tile and its location in each of the
four TMEM partitions after .warpx4.
Replication and Offset in a GPU Mesh#
The same replication structure can describe a multi-GPU layout. A GPU mesh arranges multiple
GPUs along one or more logical device axes. A 2×2 GPU mesh contains four GPUs, each identified by
coordinates (@gpuid_x, @gpuid_y).
First define a base layout sharded along @gpuid_y:
base = S[(2, 4, 8) : (1@gpuid_y, 8@m, 1@m)]
Call the three logical coordinates (y, row, col). In the base layout, element (1, 2, 3) maps to:
gpuid_y = 1
m = 2·8 + 3 = 19
Adding replication gives:
base + R[2 : 1@gpuid_x]
Element (1, 2, 3) → devices {(0, 1), (1, 1)}, local offset = 19
The term R[2 : 1@gpuid_x] places the element at both gpuid_x = 0 and gpuid_x = 1. A fixed
offset behaves differently:
base + O[1@gpuid_x]
Element (1, 2, 3) → device (1, 1), local offset = 19
This offset translates the base location by one position along @gpuid_x; it does not create a
copy. The figure below compares these two cases with a fully sharded layout. Use the controls to
switch among fully sharded, shard + replica, and shard + offset.
Click any cell to see which devices hold the corresponding logical element.
Swizzle Layout#
The final layout in this chapter addresses bank conflicts in shared memory.
GPU shared memory is divided into memory banks. Each bank can be viewed as an independent channel that serves memory accesses. Accesses to different banks can proceed in parallel. If several lanes access different addresses in the same bank at the same time, however, the hardware must serve those accesses in separate batches, producing a bank conflict.
Tensor programs often access the same tile in more than one direction. Matrix code may read a contiguous row at one point and extract a column at another. A simple layout usually favors only one of these patterns. In a row-major tile, adjacent elements in a row have consecutive addresses and usually spread across different banks. Adjacent elements in a column are separated by a row stride. If that stride matches the bank-mapping period, accesses from several lanes can concentrate in the same bank. A column-major layout has the opposite tradeoff.
Swizzling mitigates this problem by changing the physical address arrangement while preserving the tile’s logical shape. A common technique XORs part of the row index into the column index so that the target access pattern spreads more evenly across the banks.
In the 8×8 example below, map logical coordinates (row, logical_col) as:
mapped_col = logical_col XOR row
physical_addr = row·8 + mapped_col
XOR is bitwise exclusive OR. When reading logical column logical_col = 0, rows 0…7 produce
mapped_col = 0 XOR row = 0…7. Elements in one logical column therefore land in different physical
columns and, in turn, different banks.
Click a column index to compare the bank mapping of the plain row-major layout with the XOR swizzle. The former takes eight cycles; the latter takes one.
For comparison, the following official NVIDIA PTX ISA figure shows the K-major 128B swizzling layout. It corresponds directly to the right-hand “With Swizzle (XOR)” panel above: both use the same XOR rule to permute the eight positions in each row.
K-major 128B swizzling layout from the NVIDIA PTX ISA. Each cell represents one 128-bit element. Source: NVIDIA PTX ISA.
The numbers look different only because the figures use different labeling schemes. In every row,
our demo uses 0–7 to show each element’s original logical column. The official figure numbers the
entire 8×8 matrix consecutively from 0 to 63.
For example, row 1 in our demo contains the logical column labels
1, 0, 3, 2, 5, 4, 7, 6. The official figure adds that row’s index offset of 8 to the same
arrangement, producing 9, 8, 11, 10, 13, 12, 15, 14.
We call each 128-bit cell in the figure a 16 B sector. In SWIZZLE_128B, each row of an atom
contains eight sectors, for a total width of 128 B. At the common 4-byte bank granularity, one sector
spans four banks, so a full row covers all 32 banks. The swizzle uses the row coordinate to
XOR-permute the eight sectors within that row.
A SWIZZLE_128B atom contains eight rows, so its total size is 8 × 128 B = 1024 B. Here,
128 B is the width of each atom row along the contiguous dimension, not the total atom size. The
atom is the smallest repeating block of the address permutation; larger tiles are formed by tiling
multiple atoms.
Each cell in the figure represents one 16 B sector. Step through the read cycles to see how XOR distributes a column access across different banks.
Other swizzle modes use the same hierarchy with a different row width. The atoms for
SWIZZLE_64B and SWIZZLE_32B are 8 × 64 B and 8 × 32 B, respectively.
The figure below compares these atoms directly and also includes a 16 B interleaved mode with no XOR swizzle.
Choose a swizzle format and data type to see the corresponding atom shape (8 × N B). Hover over a
cell to see where that element is remapped within the atom.
Which swizzle mode should you choose? A practical rule is to use the atom with the largest row width
that the tile can support. An atom whose row is N bytes wide requires the tile’s contiguous
dimension to be at least N bytes and preferably divisible by N.
For a row at least 128 bytes wide, or 64 float16 elements, SWIZZLE_128B is usually the preferred
choice. If the contiguous dimension is narrower than 128 bytes, use the largest supported
alternative: SWIZZLE_64B or SWIZZLE_32B.
For the fp16 access pattern shown above, SWIZZLE_128B makes both contiguous row reads and column
reads across eight rows conflict-free. This guarantee applies only when the element width, swizzle
mode, and access pattern match the hardware descriptor. Changing the element width, alignment, or
access pattern may reintroduce conflicts.
In practice, programmers do not compute swizzled addresses by hand. The full mapping can be viewed
as two steps: S[...] first maps a logical element to a linear memory address on @m, and the
swizzle then rearranges that address. Because the XOR permutation is not affine, the swizzle is not
part of the affine layout itself; it is a separate address transformation composed with that layout.
Every operation that accesses the same tile must use the same swizzle mode. The composed layout handles the actual address transformation. Different hardware units impose different swizzle requirements, and those requirements also change across GPU generations. The next chapter examines those constraints.